Сторыборд да відэа: бачу ўвесь ролік загадзя — і праўлю сцэнар, пакуль гэта танна
Самае таннае месца, дзе можна паправіць ролік, — пакуль ён яшчэ не ролік. Раней я гэтага не разумеў: гнаў ідэю ў відэа амаль напрамую. Згенерую хвіліну дарагога відэа — і толькі там бачу, што сцэна не чытаецца. Далей перарабляй, час, грошы. Цяпер паміж сцэнарыстам і відэамадэллю ў мяне стаіць яшчэ адзін пласт — раскадроўка. Ён усё і змяніў.
У першай частцы я выбіраў сцэнарыста — выклік LLM, які з ідэі ў адзін радок збірае шот-ліст на кожную сцэну. У другой — відэамадэль, якая гэты шот-ліст ажыўляе. Паміж імі быў правал: сцэнарыст аддае тэкст, відэамадэль адразу малюе фінальнае відэа, а ўвесь высокаўзроўневы ролік у галаве я не бачу — толькі асобныя апісанні кадраў. Раскадроўка гэты правал закрыла.
Што гэта за пласт
Раскадроўка — гэта алоўкавы сторыборд па шот-лісце: тыя ж сцэны, але намаляваныя. Не фінальнае відэа, а хуткі чорна-белы накід: што ў кадры, хто гаворыць, куды рухаецца. Адна карцінка на ўвесь ролік. Я гляджу на яе — і ўпершыню бачу сваю ідэю цалкам, да таго як патраціў хоць секунду генерацыі відэа.
Гучыць як дробязь. На справе гэта розніца паміж «спадзяюся, атрымаецца» і «бачу, што атрымаецца».
Як гэта эвалюцыянавала
Адразу так не запрацавала. Сторыборд прайшоў чатыры стадыі, і кожная дадавала тое, чаго мне не хапала, каб «убачыць» ролік.
Стадыя 1. Толькі ключавыя кадры
Спачатку я прасіў па адным кадры на сцэну — стартавую позу. Атрымліваў акуратныя карцінкі і амаль нічога не разумеў. Персанаж ёсць, руху няма. Куды ён ідзе, што робіць, чым сцэна заканчваецца — незразумела.

Тры сцэны, па адным кадры. Відаць героя і абстаноўку, але рытму роліка не відаць.
Стадыя 2. Рух: START → PEAK
Тады я разбіў кожную сцэну на два кадры — пачатак (START) і пік (PEAK) — і паставіў паміж імі стрэлку. Адразу стаў чытацца рух: робат сядзіць → робат заглядвае ў кубак. Балоны я пакуль пакінуў пустымі, як загатоўкі: месца пад рэпліку ўжо відаць, тэксту яшчэ няма.
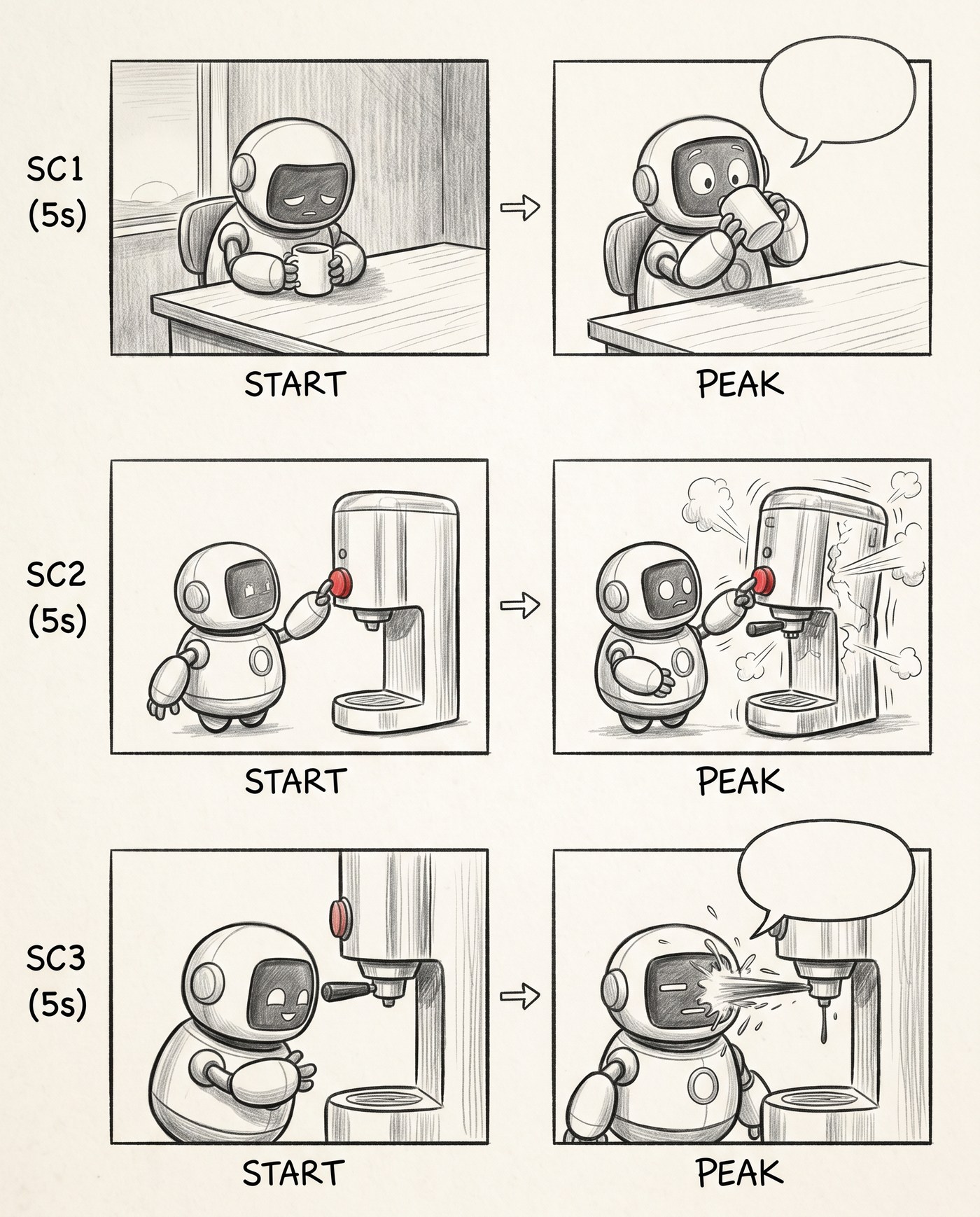
Усярэдзіне сцэны з'явіўся рух. Пустыя балоны — месцы пад рэплікі.
Стадыя 3. Рэплікі на месцах
Далей я папрасіў упісаць дакладныя рэплікі — тыя самыя, што выдаў сцэнарыст. «Empty... again?!», подпіс-нарратар «It had waited all night for this.», фінальнае «...worth it.». Вось тут ролік упершыню загучаў у галаве: чытаю сторыборд злева направа, зверху ўніз — і прайграваю ўсю сцэну з дыялогам. Слабую рэпліку ці абвіслы біт цяпер відаць вачыма, а не ўгадваеш.
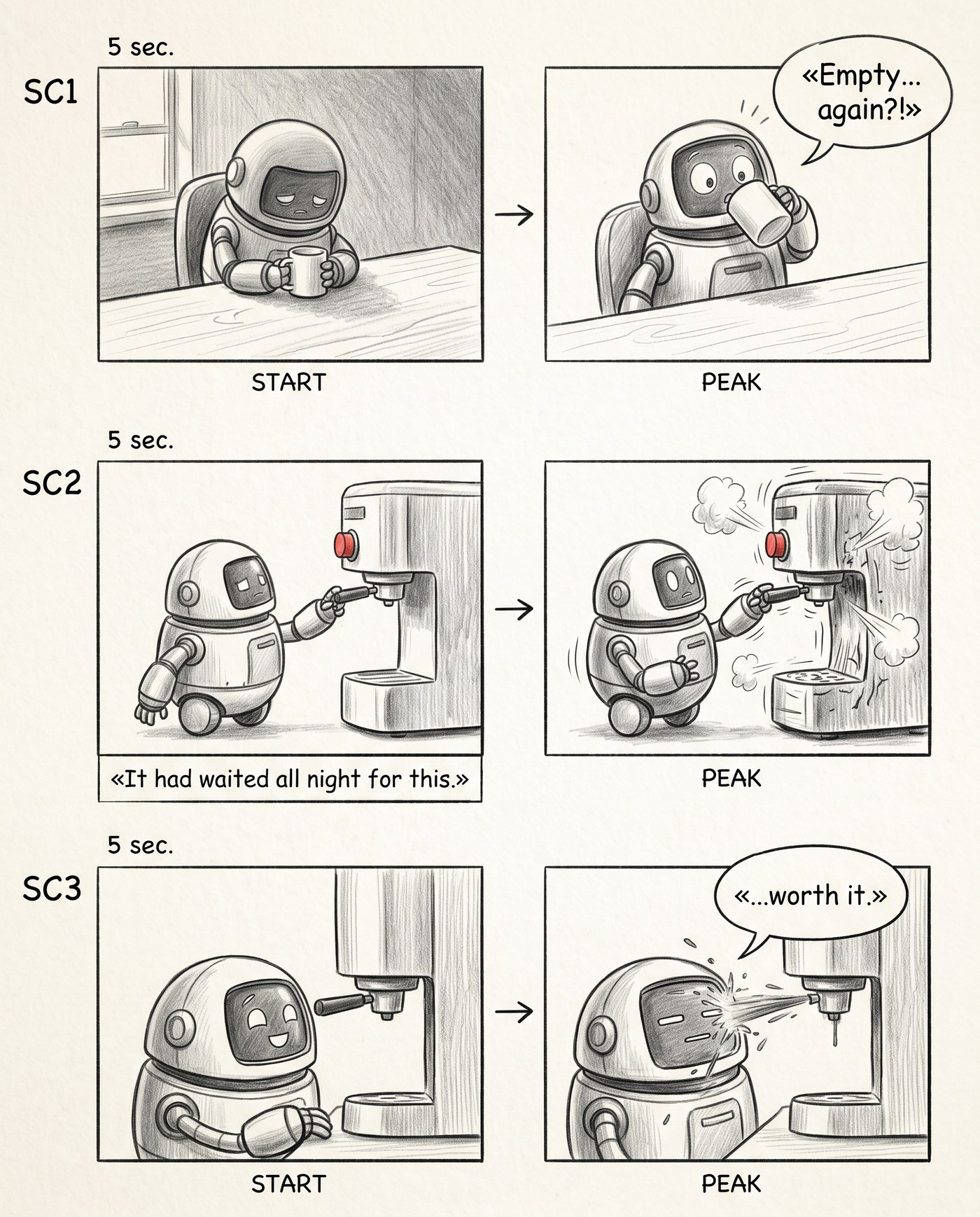
Рэплікі з шот-ліста на месцах. Ролік чытаецца цалкам — са гукам у галаве.
Стадыя 4. Каст
Апошняе, чаго не хапала, — кіруемы каст. Адзін герой яшчэ нічога, але як толькі ў кадры двое, мадэль пачынае іх блытаць: то кот рыжы, то шэры, то наогул іншы. Я дадаў у промпт другога персанажа і вузкую палосу CASTING справа — міні-партрэты герояў. А каб яны не плылі ад кадра да кадра, даў мадэлі рэферэнсы на ўваход:

Уваход каста: два рэферэнсы. Па іх мадэль трымае знешнасць герояў ва ўсіх кадрах.
Вынік — сторыборд, дзе робат і кот пазнавальныя ад першага кадра да апошняга, а збоку вісіць «каст», як у сапраўднай прэ-прадакшн-раскадроўцы.
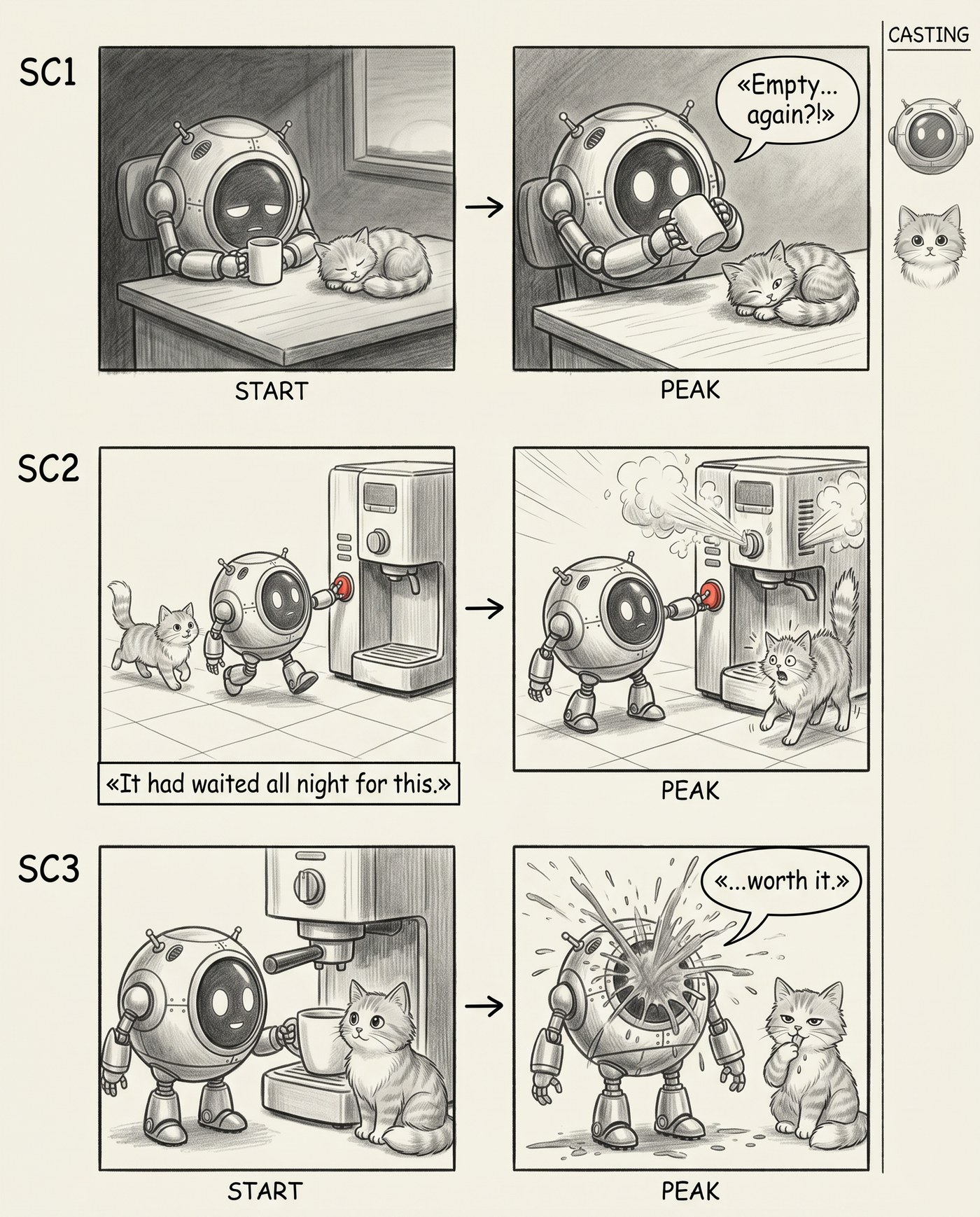
Двое герояў, абодва стабільныя паміж кадрамі, і палоса CASTING справа.
Навошта мне гэта
Я цяпер бачу ўвесь высокаўзроўневы ролік да генерацыі відэа. І гэта дае адно, але вялікае: я праўлю сцэнар, пакуль гэта танна.
Што я лаўлю на сторыбордзе:
- пусты біт — сцэна ёсць, а ўсярэдзіне нічога не адбываецца;
- не тую рэпліку — тэкст плоскі ці гаворыць не той персанаж;
- страту героя — нехта выпаў з кадра ў самы важны момант;
- збіты каст — персанаж «паплыў» знешне.
Любую з гэтых штук на гатовым відэа я чыніў бы перагенерацыяй — гэта час і грошы. На сторыбордзе я мяняю радок у шот-лісце і перазбіраю карцінку за капейкі. Гэта мой танны перадпрагляд усяго ролліка і кропка, дзе сцэнар яшчэ пластычны.
Промпты
Увесь сторыборд трымаецца на адным промпце да image-мадэлі. Вось база — варыянт без каста, адзін герой (пераносы радкоў дадаў для чытальнасці, тэкст промпта даслоўны):
Hand-drawn graphite pencil storyboard, monochrome grayscale,
professional film pre-production look, soft pencil shading on
off-white paper. NO color.
Draw a speech balloon or a narrator caption box ONLY on panels
explicitly marked below; where text is specified, render that EXACT
text accurately and legibly. A speech balloon is rounded with a tail
to a character; a narrator caption box is a plain rectangle along the
panel bottom, never attached to a character.
LAYOUT: 3 horizontal rows stacked top-to-bottom, ONE ROW PER SCENE.
Put ONLY the scene number (SC1, SC2, …) in the left margin of each row.
Inside each row draw the panels left-to-right at equal size, with a
small hand-drawn arrow pointing from each panel to the next so the
motion reads as a left-to-right progression. Beneath each panel write
its phase word EXACTLY ONCE: only START under the left panel and PEAK
under the right panel. Do NOT write any other words, numbers or labels
on or inside the panels. Keep every character visually consistent
across all panels.
SC1 (5s): START — a small round robot sits slumped at a wooden desk at
dawn, holding an empty white mug, its screen-face dim; PEAK — it lifts
the mug and peers inside, two wide surprised eyes lighting up. On the
PEAK panel draw a speech balloon with a tail to the character: «Empty...
again?!».
SC2 (5s): START — the robot rolls up to a tall chrome coffee machine,
reaching for a big red button; PEAK — it jabs the button, the machine
shudders and rattles, steam bursting from its seams. On the START panel
draw a narrator caption box along the bottom edge (a plain rectangle,
not a speech balloon): «It had waited all night for this.».
SC3 (5s): START — the robot leans in close to the machine's spout,
screen-face hopeful; PEAK — a jet of coffee sprays it full in the face,
its screen-face freezing into a flat line. On the PEAK panel draw a
speech balloon with a tail to the character: «...worth it.».Што тут робіць працу:
- грэйскейл і «NO color» — гэта прэ-прадакшн-накід, колер тут толькі замінае;
- LAYOUT — жорстка задае сетку: рад на сцэну, два кадры, стрэлка, подпісы START/PEAK і больш ніякіх лішніх надпісаў;
- balloon vs caption box — рэпліка героя малюецца аблачкам з хвосцікам, закадравы тэкст — плашкай знізу; мадэль не павінна іх блытаць;
- дакладны тэкст у «ёлачках» — рэплікі прашу ўпісаць даслоўна, у двукоссі-ёлачках, каб потым зверыць з шот-лістам вачыма.
Каб дадаць другога героя, я дапісаў да таго ж промпта каст. У шапку — што персанажаў цяпер двое і абодва павінны заставацца пазнавальнымі. У кожную сцэну дадаў дзеянні ката: спіць на стале, трушчыць побач, сядзіць і глядзіць. А справа — палоса CASTING з рэферэнсамі:
There are two recurring characters, a small round robot and a fluffy
cat; keep BOTH visually consistent across every panel.
On the right edge, a narrow vertical CASTING strip separated by a thin
line, with a small reference headshot of each main character drawn in
the same graphite pencil style; use the attached reference images for
the characters' appearance.Далей — што з гэтага атрымліваецца ў розных мадэляў.
Бонус: чым маляваць сторыборд
Адзін і той жа сторыборд я прагнаў праз чатыры image-мадэлі ў двух варыянтах промпта: без каста (адзін робат) і з кастам (робат, кот і палоса CASTING). Патрабаванні для ўсіх аднолькавыя — грэйскейл, дакладныя рэплікі, сетка START→PEAK. Глядзеў на чатыры рэчы: ці выконвае мадэль інструкцыі (грэйскейл, наратыў), ці трымае дакладны тэкст, ці не плыве каст паміж кадрамі і наколькі жывы малюнак.
Без каста: адзін герой

Nano Banana Pro: чыстая сетка, рух чытаецца, тэкст на месцы.

GPT Image 2: самая багатая графіка — фактура алоўка, фон, дэталі. Рэплікі толькі без ёлачак.

Seedream 4.5: малюнак сімпатычны, але кнопка — чырвоная. Промпт прасіў грэйскейл і «NO color» — мадэль гэта парушыла.
З кастам: робат і кот
Тут складаней: двое герояў, іх трэба трымаць аднолькавымі ва ўсіх кадрах, плюс адмаляваць палосу CASTING па рэферэнсах.

Nano Banana 2: абодва героі стабільныя, каст на месцы, рэплікі даслоўна з ёлачкамі. На гэтай мадэлі я цяпер і працую.

GPT Image 2: дэталізацыя лепшая з усіх — але рэплікі зноў без ёлачак, і кадр прыкметна шчыльнейшы.

Nano Banana Pro: чыста і акуратна, каст трымаецца. Па маім вопыце — павольней і даражэй за астатніх.
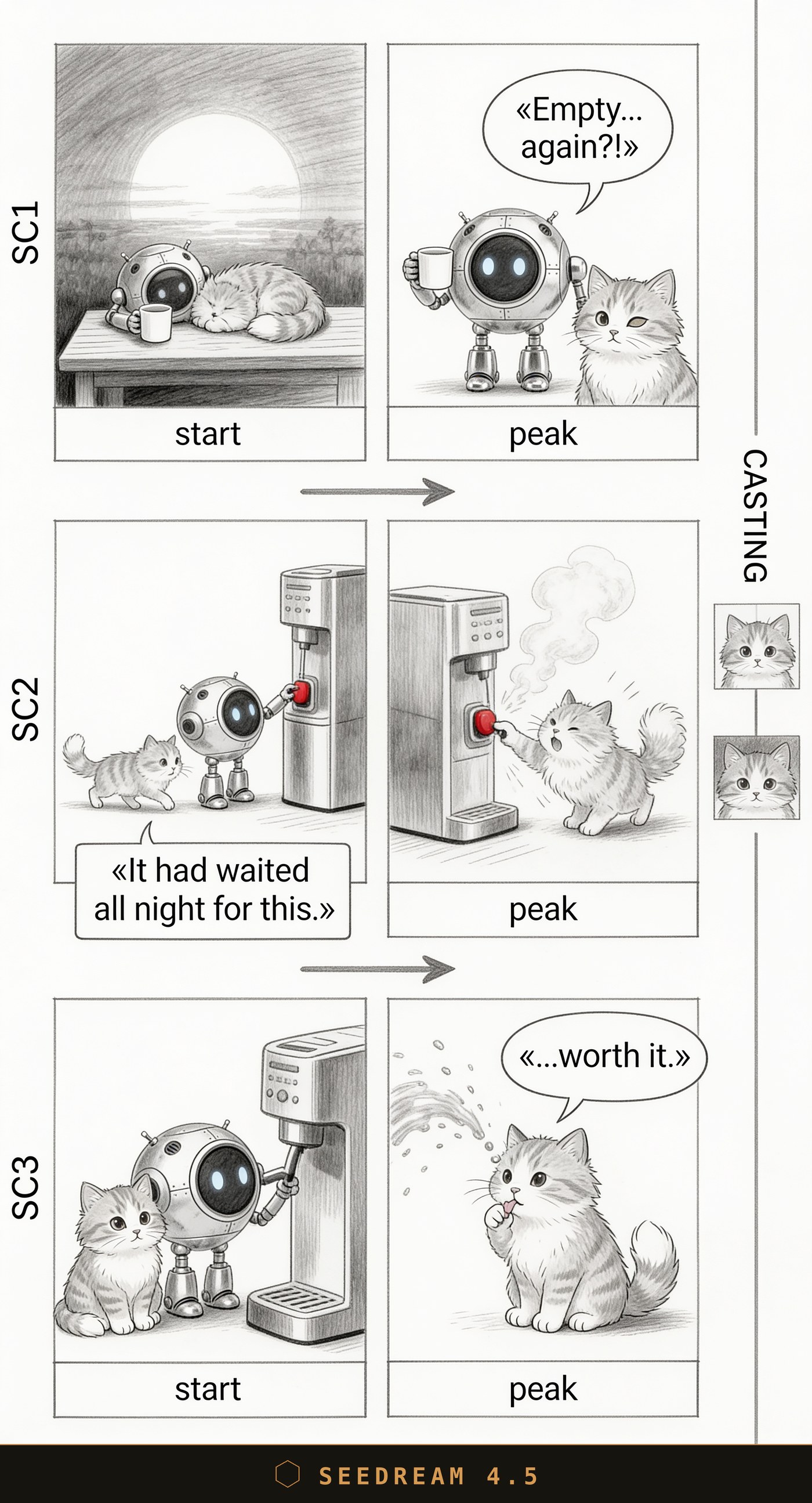
Seedream 4.5: а вось тут крытычная памылка. На фінальным кадры робат наогул прапаў, а яго рэпліку «...worth it.» аддалі кату. Жарт пра аблітага кавай робата зламаны — галоўнага героя ў панчлайне няма.
Кароткі вынік
| Мадэль | Моцнае | Слабае | Дзе ў мяне |
|---|---|---|---|
| Nano Banana 2 | Стабільны каст, даслоўны тэкст з ёлачкамі, чыстая раскадроўка | — | Працоўны выбар цяпер |
| GPT Image 2 | Лепшая дэталізацыя і фактура | Рэплікі без ёлачак, кадр шчыльнейшы | Параю, калі выйдзе танней за Nano Banana 2 |
| Nano Banana Pro | Чыста, каст трымаецца | Па вопыце павольней і даражэй | Запас, калі не шкада часу |
| Seedream 4.5 | Прыемны «скетчавы» стыль | Крытычныя памылкі: чырвоная кнопка замест грэйскейла, губляе героя і аддае рэпліку не таму | Міма — памылкі ломяць сцэну |
Выснова простая. Для раскадроўкі мне важней за ўсё, каб мадэль роўна рабіла, што просяць: трымала грэйскейл, дакладны тэкст і каст. Па гэтым крытэрыі Nano Banana 2 у мяне цяпер у прадзе — яна не памыляецца на галоўным. GPT Image 2 малюе прыгажэй за ўсіх, і калі акажацца танней, я параю яе за дэталізацыю. Nano Banana Pro — моцны запас, але павольней і даражэй. Seedream 4.5 адклаў: стыль прыемны, але крытычныя памылкі на сцэне мне даражэй за прыгажосць.
Што ў выніку атрымалася
Раскадроўку я праверыў, пару рэплік у сцэнары паправіў — і аддаў сцэну відэамадэлі. Той самай Seedance 2.0, на якой спыніўся ў другой частцы. Вось вынік: той самы робат, той самы кот, тыя самыя біты — толькі ўжо ў колеры і са гукам.
Ад шэрага алоўкавага плана да гатовага кадра. Сцэнар я ўзгадніў яшчэ на сторыбордзе — відэамадэлі засталося толькі адмаляваць.
Дзе гэта ў серыі
Склалася ланцужок. У першай частцы я выбіраў сцэнарыста — ён задае столь якасці тэксту. У другой — відэамадэль, яна яго выконвае. Раскадроўка стала паміж імі: пласт, дзе я нарэшце бачу ўвесь ролік загадзя і магу яго паправіць, пакуль праўка каштуе капейкі. Раней я давяраў пайплайну ўсляпую. Цяпер гляджу і вырашаю.