My Architect, part 8: Event Storming as sequence control, not another diagram
This is the eighth post in the series about My Architect. For anyone who hasn't read the earlier parts, in short: My Architect is a system where the project lives between an AI agent's sessions. One side faces the agent — it runs the project through MCP; the other faces the human — a visual interface shows what the agent has already done and the whole project's progress. This post is about one concrete mechanism of that control.
The showcase here is Forklift, a mid-sized food-delivery domain of five bounded contexts. Every board, every analyzer number and every DSL snippet below is real: the project is seeded locally and runs through the actual analyzeEsSequence. Nothing is made up.
A diagram for the diagram's sake is useless. Sequence control isn't
We all have that graveyard. A docs/architecture folder with pretty PNGs drawn six months ago, and not one of them matches the code anymore. A picture-diagram is a snapshot of someone's good intentions at time T. It checks nothing. It doesn't know you forgot to wire up the cancellation branch. It will cheerfully show an arrow that isn't in the code and stay silent about the fifteen that are.
So when I say "the agent draws an Event Storming board," your eye twitches, and fairly so. Another picture? No. The difference is one word: sequence.
Event Storming isn't a diagram of boxes. It's a story laid out in time: how an event triggers a reaction, the reaction a command, the command a new event. A domain event ("Order placed") has a cause. A command ("Place order") has a result. A policy ("As soon as payment is authorized → confirm the order") is the bridge between someone else's event and your command. And that property — everything has a cause and an effect — turns from nice philosophy into a machine-checkable invariant.
An event hanging without a cause is a gap. A command that produces no event is a gap. A policy that bridges nothing is a gap. An isolated card means someone sketched a thought and never finished it. These gaps aren't visible to the eye on a board of forty stickies. But they are visible to an analyzer that reads the sequence graph.
The showcase is appetizing — Forklift: on-demand food delivery, from tap to doorstep. Five bounded contexts: Ordering, Payments, Kitchen, Dispatch, Tracking. Exactly the class of domain where "forgot to wire up a branch" costs real money: the food is cooked but the money wasn't charged; no courier was assigned and the customer complains.
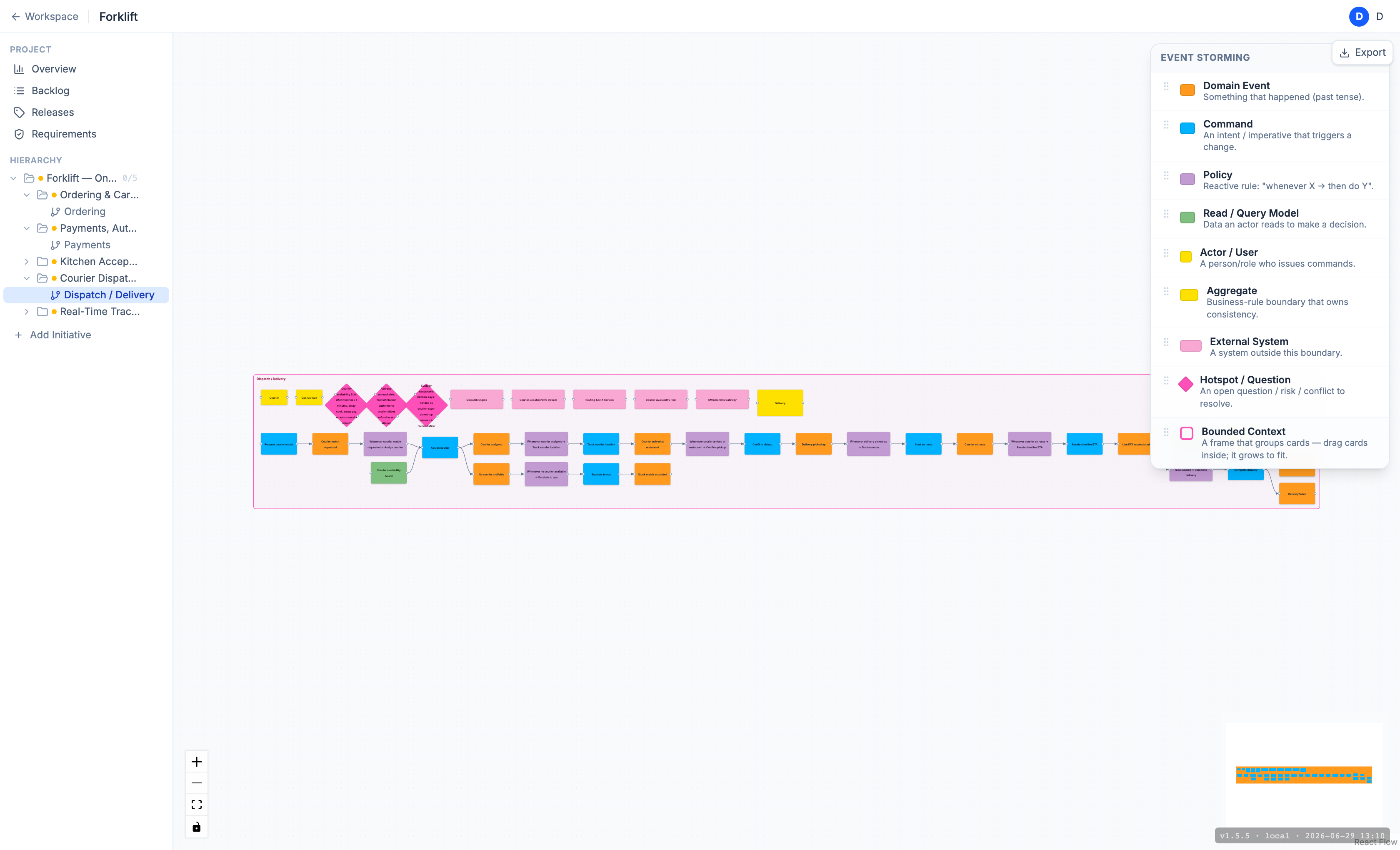 The Dispatch context: commands (blue) → events (orange), bridging policies (lilac), read models (green), external systems (pink), actors (yellow), and the open questions — hotspots (diamonds) along the bottom.
The Dispatch context: commands (blue) → events (orange), bridging policies (lilac), read models (green), external systems (pink), actors (yellow), and the open questions — hotspots (diamonds) along the bottom.
Why this gives an agent leverage specifically
A human looks at the board and feels something is missing. Sometimes finds it. More often doesn't: attention doesn't scale, and by the thirtieth card you no longer remember whether you closed the outcome of the "Reject order" command.
An agent doesn't feel. An agent runs a deterministic graph check. analyzeEsSequence walks the cause-and-effect graph of the board and returns a structured verdict: ok, a list of gaps with a type (isolated, event-without-cause, command-without-effect, policy-not-bridging) and a level (warning / info), and separately — openQuestions (the hotspot cards).
That's the leverage. The agent gets a feedback loop that doesn't lie and doesn't tire:
- Author — the agent authors the board via
create_diagram(diagramType:'event-storming', nodeId), pinning it to a hierarchy node (an epic or initiative). - Validate — reads it back via
get_diagram; thesequencefield shows the gaps in the story. - Refine — fixes via
update_diagramand validates again, untilgapscollapses to zero. - Re-validate during implementation — while building, it reruns the check: the code drifted from the story → the board turns red again.
The agent doesn't try to be clever by eye. It leans on a cheap deterministic check and iterates to green — exactly the way it iterates tests.
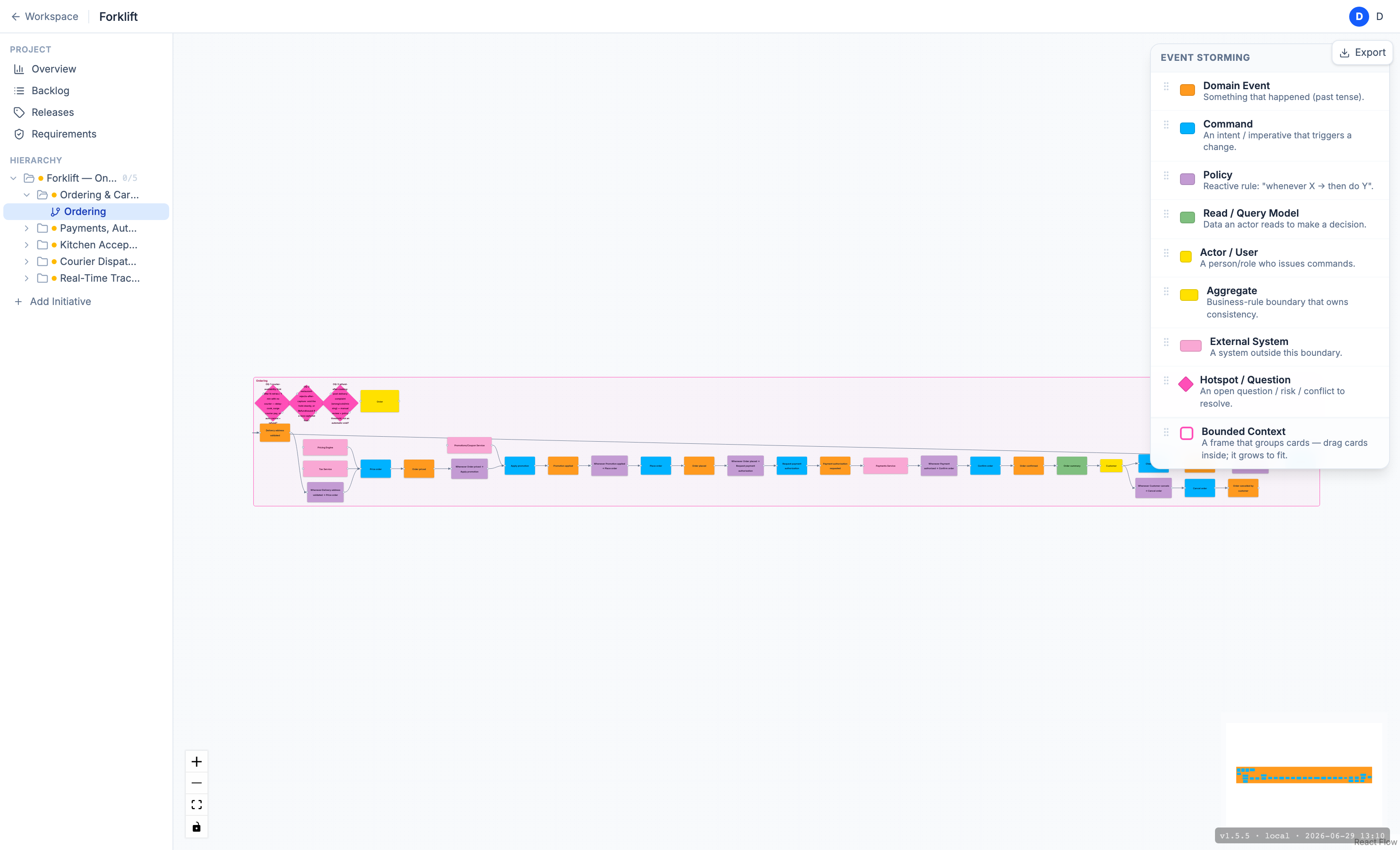
The loop in action: Ordering, from rough draft to clean story
First the agent sketched v0 of the Ordering context — an honest draft, the kind a live human throws down: grabbed the main thread, marked "the answer from Payments comes back here," and never finished the tail.
event-storming
# excerpt: only the main Ordering thread is shown; the board has more cards
group "Ordering"
[command] "Place order"
[event] "Order placed"
[policy] "Whenever Payment authorized → Confirm order"
[command] "Confirm order"
[event] "Order confirmed"
[command] "Cancel order"
connect "Place order" -> "Order placed"
# "Whenever Payment authorized → Confirm order" — connected to nothing (isolated policy)
# "Cancel order" — neither incoming nor outgoing (isolated command)
# "Order confirmed" — no incoming cause (event-without-cause, info)The agent reads get_diagram, runs the analyzer, and gets this for v0:
27 cards · 19 connections · 1 contexts — 2 sequence gap(s), 0 open question(s)
gaps:
• "Whenever Payment authorized → Confirm order" (policy) is not connected to anything
• "Cancel order" (command) is not connected to anythingTwo warning gaps (the isolated return policy from Payments and the unclosed cancellation tail) plus one info note ("Order confirmed" without a cause — the producing command isn't wired in). Then comes refine: the agent wires in the producing command, bridges the policy into the confirm command, and closes the cancellation tail with a resulting event. Re-validating v1:
34 cards · 30 connections · 1 contexts — 0 sequence gap(s), 3 open question(s)The gaps collapsed. But — and this is the point — the board didn't go empty and didn't start lying "all solved." Exactly three cards remain that the agent deliberately left red. More on them below.
The same loop on Payments: where the draft is especially dangerous
Payments is the context where a half-drawn arrow means "the food is cooked, the money wasn't taken" or "the money was charged twice." Here v0 was leaky, and that's fine: that's exactly why the check exists.
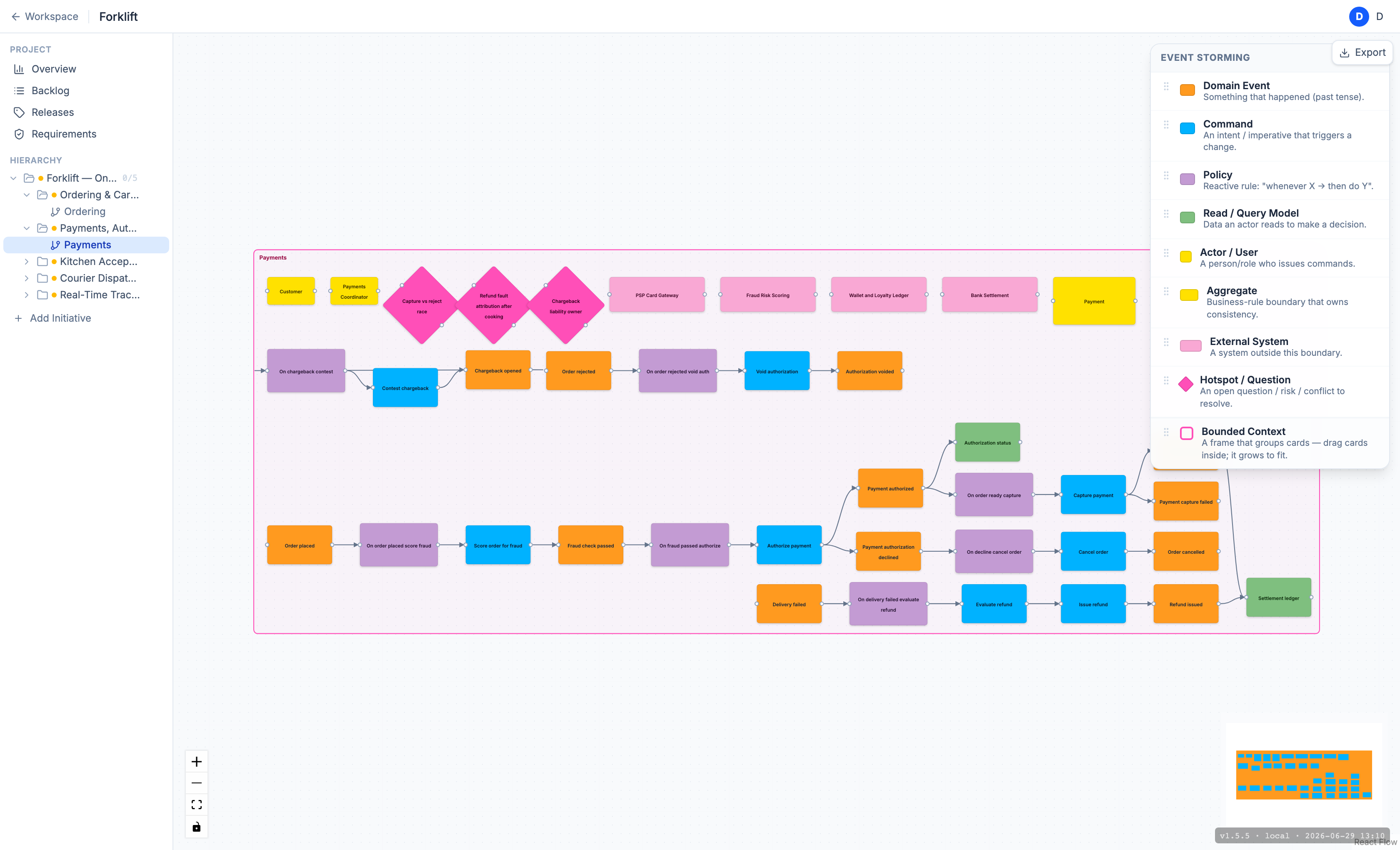
The analyzer's verdict on Payments v0:
25 cards · 15 connections · 1 contexts — 3 sequence gap(s), 0 open question(s)
gaps:
• "Issue refund" (command) is not connected to anything — the refund path drawn halfway
• "Chargeback opened" (event) is not connected to anything — a forgotten denial branch
• "On decline cancel order" (policy) missing outgoing command — the bridge to cancellation left at the seamAfter refine the agent closes the refund path (Evaluate refund → Issue refund → Refund issued), wires in chargeback handling, and completes the decline-policy bridge into Cancel order. The verdict on v1:
39 cards · 27 connections · 1 contexts — 0 sequence gap(s), 3 open question(s)And again — three cards stay red on purpose (the capture-vs-reject race, fault attribution on a refund, the liability owner on a chargeback).
The other three contexts: the same pattern
The loop is the same everywhere. What the analyzer caught in v0 — and what it collapsed to in v1:
| Context | v0 (gaps) | v1 | What was broken in v0 |
|---|---|---|---|
| Ordering | 2 → | 0 | isolated return policy; unclosed cancellation tail |
| Payments | 3 → | 0 | severed refund path; forgotten chargeback; decline bridge left at the seam |
| Kitchen | 5 → | 0 | Reject order/Order rejected orphaned; time-estimate policy with no trigger; Start cooking with no event; Cooking started isolated |
| Dispatch | 4 → | 0 | Notify ops with no outcome; orphaned tracking policy; Courier arrived/Delivery failed without a cause |
| Tracking | 3 → | 0 | notification policy with no trigger; Recalculate ETA isolated; rating-request policy not wired in |
Project total: 17 mechanical gaps caught and closed, 15 open questions deliberately left in view. Not a single invented number — this is the output of the real analyzeEsSequence over the seeded boards.
What stays an open question — and why that's a feature, not a bug
Here's the core idea. When gaps collapsed to zero, a naive system would be tempted to say "the architecture is done." That would be a lie. The difference between a gap and an open question is fundamental:
- A gap is a mechanical loose end. An arrow you forgot to draw. Fixed in DSL in a minute. It needs no decision — it needs care. This is exactly what the analyzer must catch and demand you fix.
- An open question (hotspot) is an unresolved business decision. You can't "fix" it by drawing an arrow, because it isn't yet chosen which arrow to draw. Masking it with "green" means silently making the decision for the product owner. The worst thing architecture can do.
So hotspots are first-class citizens of the board. They pass validation (ok=true) but stay in view as openQuestions. The board says honestly: "mechanically I'm connected, but these forks are waiting on a human."
And the loveliest part: one business question surfaces as a hotspot from both sides of the seam — the same question is visible from several contexts at once. That's not duplication, it's a map of who a decision will touch once the product owner finally makes it:
- Courier availability (SLA). "After N retries / T minutes with no courier — hold cooking, raise courier pay, or auto-cancel + refund?" Visible in Dispatch (
No courier available), Ordering (Hold or auto-cancel) and Payments (the refund branch) at once. - The capture-vs-reject race. "If the restaurant's rejection arrived after the charge — is it a void on the hold, or already a RefundIssued?" Hanging in Payments, Kitchen and Ordering. One race condition that no one has resolved yet — and the board won't let you forget it.
- Fault attribution on a post-cooking refund (customer / courier / restaurant-fault) — a hotspot in Payments, Dispatch and Tracking at once, because the manual-review threshold isn't set yet.
- Notification fallback (what to do when the Push/SMS/Email gateway fails) and ETA staleness — honest open questions in Tracking that the analyzer doesn't mask.
A green analyzer doesn't mean "the decisions are made." It means "the story is mechanically connected, and every unresolved fork is explicitly raised to the surface instead of drowned in silence." That's exactly the boundary you want between what the agent may build on its own and where it must call a human.
The artifact: these aren't pictures, it's a working project
Everything above isn't a mockup in a graphics editor. It's a seeded project that opens in the product:
- Forklift — an initiative and 5 epics (one per bounded context), each epic owning its own Event Storming board.
- 178 cards, 142 connections across five boards; every board passes
analyzeEsSequencewith zero warnings and threeopenQuestions. - The boards are pinned to hierarchy nodes — which means "v0 → v1" isn't a one-off cleanup but a living control: when the code drifts from the story, the board turns red again.
How to try it yourself — already possible
This isn't "we'll ship it someday." The whole toolchain is updated and available right now:
- The app — the
event-stormingtype is rolled out on my-architect.app: boards render, lay out along the causal graph (ELK), and are created straight from the hierarchy (node → "+" → Event Storming). - The MCP —
@my-architect/mcp@1.6.1is published on npm: the toolscreate_diagram(diagramType:'event-storming', nodeId),get_diagram(returns thesequencefield with gaps) andupdate_diagram(refine + re-analyze). - The skill —
my-architectv1.11.0 in the marketplace: it carries the rule "for an epic or initiative, run Event Storming as a sub-task by default and re-validate the sequence during implementation."
Installing in Claude Code:
- Create an account at my-architect.app, grab a token on the API Keys page, and export it in the same session where you run Claude Code:
``bash export MCP_API_KEY=mcp_YOUR_TOKEN ``
- Add the marketplace and install the plugin (the MCP server connects itself —
npx -y @my-architect/mcp@latest,MA_API_URL=https://my-architect.app):
`` /plugin marketplace add d7561985/my-architect-marketplace /plugin install my-architect@my-architect-marketplace ``
- Hand the agent an epic or initiative and ask it to lay out an Event Storming — it will run the
create_diagram → get_diagram (sequence) → update_diagramloop to green on its own, leaving the open questions as hotspots.
Already have the plugin? Update to the fresh tools and rule: /plugin marketplace update my-architect-marketplace → /plugin update my-architect.
Takeaway: a practice for teams
Strip away all of Forklift and keep the essence — a working recipe:
- Stop treating diagrams as pictures. Pick a format with a checkable invariant. Event Storming has one built in: everything has a cause and an effect.
- Make the sequence check cheap and deterministic.
analyzeEsSequenceover the board is a linter for architecture. Gaps (isolated,event-without-cause,command-without-effect,policy-not-bridging) are the compile errors of your story. - Give the agent a loop, not a one-off pass.
create_diagram→get_diagram(validate) →update_diagram(refine) → re-validate during implementation. The agent iterates to green the same way it iterates to green tests — without tiring, without "I think I wired it all up." - Draw a hard line between a gap and an open question. The agent fixes the gap. The open question stays a hotspot in view, waiting on a human. A system that masks the second as the first silently makes business decisions for you — the worst kind of tech debt.
- Pin the board to a hierarchy node (an epic or initiative), not to thin air.
The most valuable thing here isn't even that the agent fixes gaps. It's that it knows precisely where it must not fix — and leaves those spots red, labeled and visible. An architecture that honestly says "this part I don't know yet" is worth more than any pretty diagram that pretends to know everything.