My Architect, частка 3: мадэль планавання
Гэта трэці артыкул серыі пра My Architect. У частцы 1 я расказаў, навошта агенту памяць паміж сесіямі, у частцы 2 — як усё гэта жыве ў YAML-файлах без базы даных. Цяпер пра саму мадэль: што менавіта агент чытае і піша, калі плануе.
Агент па змаўчанні генеруе тудушкі
Папрасіце агента распланаваць праект, і ён выдасць плоскі спіс з сарака пунктаў кшталту «Implement login», «Add tests», «Fix CORS». Праз тыдзень гэты спіс бескарысны: незразумела, што ад чаго залежыць, дзе мяжа рэлізу і чаму пункт 23 увогуле з'явіўся. Агент не дурны, у яго проста няма формы, у якую можна думаць. Мадэль планавання ў My Architect і ёсць такая форма.
Іерархія: прэсеты і глыбіня
Праект — дрэва вузлоў. Глыбіню і імёны ўзроўняў задае прэсет: agile дае Epic → Feature → Story → Task, SAFe пачынаецца з Initiative (Initiative → Epic → Feature → Story), simple абмяжоўваецца двума ўзроўнямі Category → Item, а custom дазваляе назваць узроўні як заўгодна. Максімальная глыбіня роўная колькасці ўзроўняў у прэсеце, і сервер гэта ахоўвае: move_node адхіліць перанос, які выштурхнуў бы паддрэва за ліміт (памылка MAX_DEPTH_EXCEEDED).
Пры стварэнні праекта праз scaffold_project асобна выбіраецца складанасць: simple, standard або complex. Ад яе залежыць стартавы набор: для standard і complex адразу ствараюцца і WBS-дыяграма, і User Story Map.
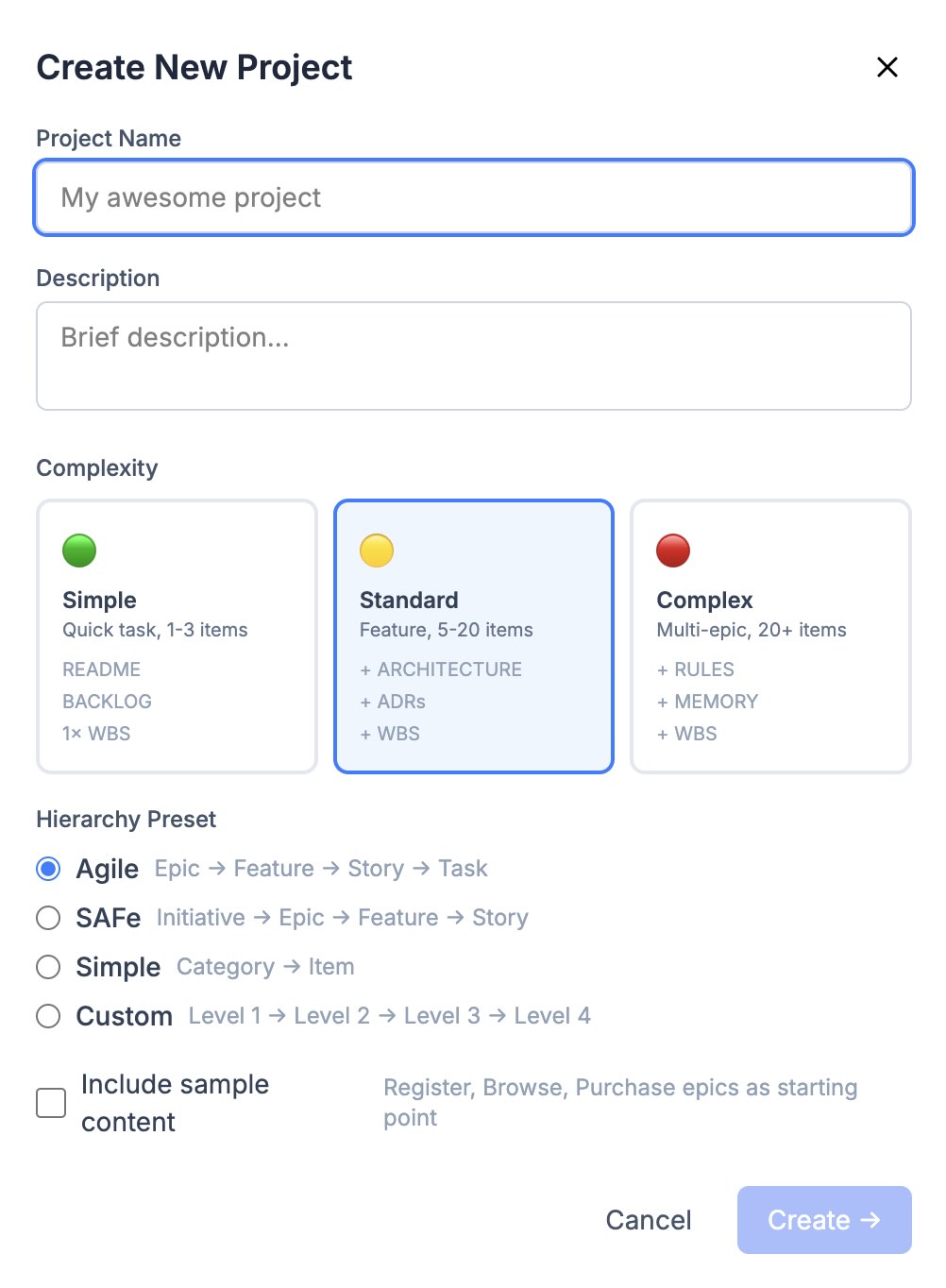
Стварэнне праекта: складанасць задае стартавы набор, прэсет — філасофію ўзроўняў: Epic → Feature → Story → Task.
Анатомія вузла
У кожнага вузла ёсць семантычны type і лікавы level, і гэта наўмысна розныя рэчы (навошта — крыху ніжэй). Статус адзін з пяці: draft, todo, in-progress, done, blocked. Прыярытэт P1–P3, прывязка да рэлізу, выканаўца ў assignee (агент або чалавек). Змесціва вузел не захоўвае ўнутры сябе, а трымае па спасылках: requirementIds для патрабаванняў, docIds для дакументаў, diagramIds для дыяграм, плюс requires — спіс патрабаванняў, якім вузел абавязаны задавальняць.
Чатыры тыпы патрабаванняў з тыпізаванымі палямі
Рашэнні ў праекце запісваюцца патрабаваннямі чатырох тыпаў, і ў кожнага тыпу свае структурныя палі, а не агульны тэкст.
- FR (функцыянальнае):
userStory,acceptanceCriteria,businessValue. - NFR (нефункцыянальнае):
metric,targetValue,measurementMethod. - SAR (архітэктурнае рашэнне):
rationale,alternatives,consequences. - CON (абмежаванне):
sourceіflexibilityса значэннямі fixed або negotiable.
Ідэнтыфікатары генеруюцца аўтаматычна па лічыльніку тыпу: FR-001, NFR-002. Агент выклікае add_requirement, і на дыску з'яўляецца прыкладна такое:
id: NFR-003
type: NFR
title: API response time
ownerNodeId: epic-payments
status: approved
fields:
metric: response time p95
targetValue: "< 200 ms"
measurementMethod: load test, 1000 concurrent usersРозніца з нататкай «API павінен быць хуткім» у тым, што ў NFR ёсць спосаб праверкі. А поле flexibility ў абмежаванняў адказвае на пытанне, якое агенты звычайна вырашаюць моўчкі і няправільна: ці можна з гэтым спрачацца. CON ад юрыстаў — fixed, CON «бюджэт на хостынг 50 долараў» — negotiable.
Спадкаванне замест капіявання
Патрабаванне належыць роўна аднаму вузлу праз ownerNodeId. Але бачнае яно ўсяму паддрэву: get_requirements з флагам inherited падымаецца па ланцужку продкаў і збірае ўсё, што вісіць вышэй. NFR «p95 менш за 200 мс», павешаны на эпік, агент атрымае з любой укладзенай задачы, хоць фізічна патрабаванне запісанае адзін раз.
Гэта вырашае класічную праблему копій. Калі б NFR дубляваўся ў кожную задачу, то пры змене мэты з 200 да 150 мс давялося б знайсці і паправіць усе копіі, і якая-небудзь абавязкова засталася б старой. Тут крыніца адна, а бачнасць вылічаецца пры чытанні. Для адваротнай сувязі ёсць tracesTo: патрабаванне можа яўна паказваць вузлы, якія яго рэалізуюць, і па гэтым полі будуецца трасіроўка.
Лінтэр назваў: вузлы называюць сутнасці
Самая спрэчная фіча па водгуках і самая карысная па факце. RFC-013 фармулюе правіла так: назва вузла называе сутнасць, якая з'явіцца ў выніку, а не працу. «Login system», не «Implement login». Лінтэр спрацоўвае проста ў build_hierarchy і update_node: дрэва з дрэннымі назвамі не створыцца, пераназываннем правіла таксама не абысці.
Што менавіта заварочваецца: імператывы ў пачатку (Add, Create, Build, Implement, Fix і падобныя), пайплайны крокаў кшталту «GET → parse → render», пералічэнні праз « + », спісы варыянтаў a/b/c, пералічэнні праз коскі, прыёмачныя крытэрыі ў дужках у канцы («(TDD, no regressions)») і назвы даўжэйшыя за дзесяць слоў. Кожная адмова прыходзіць агенту з тлумачэннем, куды падзець лішняе: крокі і прыёмку ў апісанне або патрабаванні, пералічаны аб'ём у даччыныя вузлы.
Агенты без лінтэра стабільна серыялізуюць у назву свой бягучы стан працы. Лінтэр настроены на рэальным корпусе назваў з прадакшэну і ловіць менавіта гэтыя формы. Вынік прыкметны праз месяц: бэклог з 200 вузлоў чытаецца як карта прадукту, па якой бачна, што сістэма ўмее, а не як пратакол даручэнняў, па якім бачна толькі, хто што калісьці рабіў.
User Story Map тэкстам
Канва з USM ёсць у чалавека, але агенту карцінка не патрэбная. get_usm_view аддае тую ж карту структурай: калонкі backbone па гарызанталі, палосы рэлізаў па вертыкалі. У ячэйках ляжаць карткі са статусамі і выканаўцамі. Узровень backbone вызначаецца аўтаматычна: бярэцца той, у чыіх вузлоў больш за ўсё дзяцей з прызначаным рэлізам. Карткі без рэлізу падаюць у кошык unplanned, і яго памер — сумленная метрыка таго, колькі працы яшчэ не распланавана. Па кожным рэлізе адразу лічыцца статыстыка выканання (total/done/in-progress).
Прызначэнне вузлоў у рэліз робіцца атамарна праз plan_release: усе абнаўленні сыходзяць адным bulk-запытам, а ў адказе асобныя спісы successful і failed, так што частковы збой бачны адразу.
Разумныя дробязі пры перабудове дрэва
move_node пераносіць вузел разам з паддрэвам і пералічвае ўзроўні. Цікавае ў дэталях: тып пералічваецца толькі ў тых вузлоў, чый тып да пераносу адпавядаў іх узроўню. Story, якая пераехала пад эпік, стане feature. А вузел, якому тып выставілі ўсвядомлена насуперак узроўню, свой тып захавае, і разыходжанне потым падсвеціць validate_project, а не маўклівая аўтаматыка. Цыклы (перанос пад уласнага нашчадка) адхіляюцца з CYCLE_DETECTED яшчэ да запісу.
Для выпадку «вузел ляжыць правільна, але названы не тым тыпам» ёсць асобны set_node_type: мяняецца толькі семантычны тып, а id, slug, пазіцыя, дзеці і ўсе спасылкі застаюцца на месцы.
І апошняя дробязь: WBS-нумарацыя (1.2.3) нідзе не захоўваецца. Яна вылічаецца з пазіцыі сярод siblings на ляту, таму пасля любога пераносу нумарацыя застаецца шчыльнай і без дзірак.
Што далей
Мадэль адказвае на пытанне «як зладжаны план». Наступная частка — пра тое, як агент па гэтым плане працуе: цыкл ад get_next_task да complete_task, дакументацыя як частка задачы і зверка плана з рэальным кодам. Паспрабаваць My Architect можна на my-architect.app.