My Architect, частина 3: модель планування
Це третя стаття серії про My Architect. У частині 1 я розповів, навіщо агенту пам'ять між сесіями, у частині 2 — як усе це живе в YAML-файлах без бази даних. Тепер про саму модель: що саме агент читає і пише, коли планує.
Агент за замовчуванням генерує тудушки
Попросіть агента розпланувати проєкт, і він видасть плаский список із сорока пунктів на кшталт «Implement login», «Add tests», «Fix CORS». За тиждень цей список марний: незрозуміло, що від чого залежить, де межа релізу і чому пункт 23 узагалі з'явився. Агент не дурний, у нього просто немає форми, в яку можна думати. Модель планування в My Architect і є такою формою.
Ієрархія: пресети і глибина
Проєкт — дерево вузлів. Глибину і назви рівнів задає пресет: agile дає Epic → Feature → Story → Task, SAFe починається з Initiative (Initiative → Epic → Feature → Story), simple обмежується двома рівнями Category → Item, а custom дозволяє назвати рівні як завгодно. Максимальна глибина дорівнює числу рівнів у пресеті, і сервер це охороняє: move_node відхилить перенесення, яке виштовхнуло б піддерево за ліміт (помилка MAX_DEPTH_EXCEEDED).
При створенні проєкту через scaffold_project окремо обирається складність: simple, standard або complex. Від неї залежить стартовий набір: для standard і complex одразу створюються і WBS-діаграма, і User Story Map.
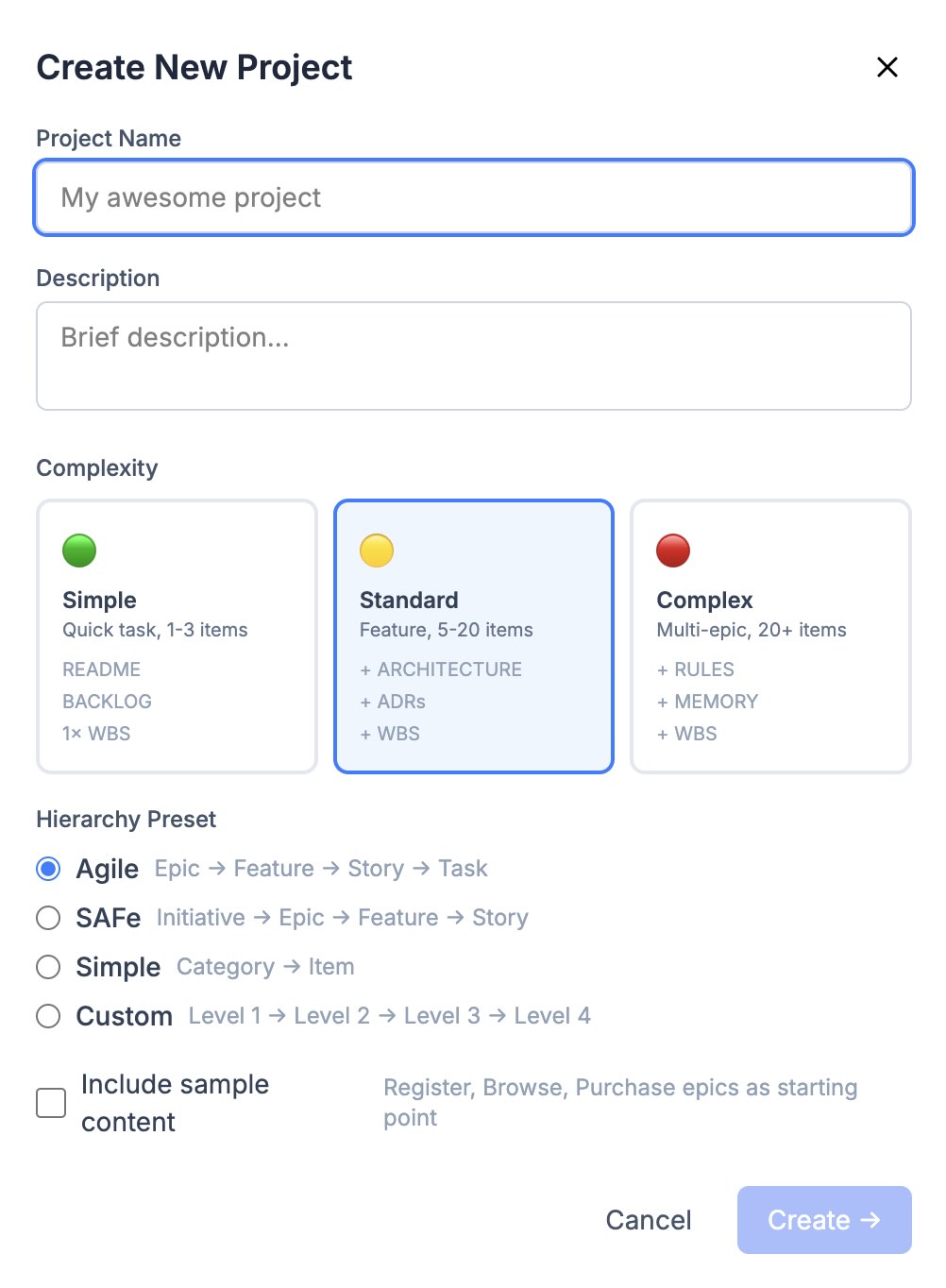
Створення проєкту: складність задає стартовий набір, пресет — філософію рівнів: Epic → Feature → Story → Task.
Анатомія вузла
У кожного вузла є семантичний type і числовий level, і це навмисно різні речі (навіщо — трохи нижче). Статус один із п'яти: draft, todo, in-progress, done, blocked. Пріоритет P1–P3, прив'язка до релізу, виконавець в assignee (агент або людина). Вміст вузол не зберігає всередині себе, а тримає за посиланнями: requirementIds для вимог, docIds для документів, diagramIds для діаграм, плюс requires — список вимог, яким вузол зобов'язаний задовольняти.
Чотири типи вимог із типізованими полями
Рішення в проєкті записуються вимогами чотирьох типів, і в кожного типу свої структурні поля, а не загальний текст.
- FR (функціональна):
userStory,acceptanceCriteria,businessValue. - NFR (нефункціональна):
metric,targetValue,measurementMethod. - SAR (архітектурне рішення):
rationale,alternatives,consequences. - CON (обмеження):
sourceіflexibilityзі значеннями fixed або negotiable.
Ідентифікатори генеруються автоматично за лічильником типу: FR-001, NFR-002. Агент викликає add_requirement, і на диску з'являється приблизно таке:
id: NFR-003
type: NFR
title: API response time
ownerNodeId: epic-payments
status: approved
fields:
metric: response time p95
targetValue: "< 200 ms"
measurementMethod: load test, 1000 concurrent usersРізниця з нотаткою «API має бути швидким» у тому, що в NFR є спосіб перевірки. А поле flexibility в обмежень відповідає на питання, яке агенти зазвичай вирішують мовчки і неправильно: чи можна з цим сперечатися. CON від юристів — fixed, CON «бюджет на хостинг 50 доларів» — negotiable.
Спадкування замість копіювання
Вимога належить рівно одному вузлу через ownerNodeId. Але видно її всьому піддереву: get_requirements із прапорцем inherited піднімається ланцюжком предків і збирає все, що висить вище. NFR «p95 менше 200 мс», повішений на епік, агент отримає з будь-якої вкладеної задачі, хоча фізично вимогу записано один раз.
Це розв'язує класичну проблему копій. Якби NFR дублювався в кожну задачу, то при зміні цілі з 200 до 150 мс довелося б знайти і поправити всі копії, і якась обов'язково залишилася б старою. Тут джерело одне, а видимість обчислюється при читанні. Для зворотного зв'язку є tracesTo: вимога може явно вказувати вузли, які її реалізують, і за цим полем будується трасування.
Лінтер назв: вузли називають сутності
Найсуперечливіша фіча за відгуками і найкорисніша за фактом. RFC-013 формулює правило так: назва вузла іменує сутність, яка з'явиться в результаті, а не роботу. «Login system», не «Implement login». Лінтер спрацьовує прямо в build_hierarchy і update_node: дерево з поганими назвами не створиться, перейменуванням правило теж не обійти.
Що саме завертається: імперативи на початку (Add, Create, Build, Implement, Fix і подібні), пайплайни кроків на кшталт «GET → parse → render», переліки через « + », списки варіантів a/b/c, переліки через коми, приймальні критерії в дужках наприкінці («(TDD, no regressions)») і назви довші за десять слів. Кожна відмова приходить агенту з поясненням, куди подіти зайве: кроки і приймання — в опис або вимоги, перелічений обсяг — у дочірні вузли.
Агенти без лінтера стабільно серіалізують у назву свій поточний стан роботи. Лінтер налаштований на реальному корпусі назв із продакшену і ловить саме ці форми. Результат помітний за місяць: беклог із 200 вузлів читається як карта продукту, з якої видно, що система вміє, а не як протокол доручень, з якого видно лише, хто що колись робив.
User Story Map текстом
Канва з USM є в людини, але агенту картинка не потрібна. get_usm_view віддає ту саму карту структурою: колонки backbone по горизонталі, смуги релізів по вертикалі. У клітинках лежать картки зі статусами і виконавцями. Рівень backbone визначається автоматично: береться той, у чиїх вузлів найбільше дітей із призначеним релізом. Картки без релізу падають у кошик unplanned, і його розмір — чесна метрика того, скільки роботи ще не розплановано. По кожному релізу одразу рахується статистика виконання (total/done/in-progress).
Призначення вузлів у реліз робиться атомарно через plan_release: всі оновлення йдуть одним bulk-запитом, а у відповіді роздільні списки successful і failed, тож частковий збій видно одразу.
Розумні дрібниці при перебудові дерева
move_node переносить вузол разом із піддеревом і перераховує рівні. Цікаве в деталях: тип перераховується лише в тих вузлів, чий тип до перенесення відповідав їхньому рівню. Story, що переїхала під епік, стане feature. А вузол, якому тип виставили свідомо всупереч рівню, свій тип збереже, і розбіжність потім підсвітить validate_project, а не мовчазна автоматика. Цикли (перенесення під власного нащадка) відхиляються з CYCLE_DETECTED ще до запису.
Для випадку «вузол лежить правильно, але названий не тим типом» є окремий set_node_type: змінюється лише семантичний тип, а id, slug, позиція, діти і всі посилання залишаються на місці.
І остання дрібниця: WBS-нумерація (1.2.3) ніде не зберігається. Вона обчислюється з позиції серед siblings на льоту, тому після будь-якого перенесення нумерація залишається щільною і без дірок.
Що далі
Модель відповідає на питання «як влаштований план». Наступна частина — про те, як агент за цим планом працює: цикл від get_next_task до complete_task, документація як частина задачі і звірка плану з реальним кодом. Спробувати My Architect можна на my-architect.app.