My Architect, część 3: model planowania, dzięki któremu agent myśli jak architekt
To trzeci wpis z serii o My Architect. W części 1 opowiedziałem, po co agentowi pamięć między sesjami, w części 2 — jak to wszystko żyje w plikach YAML bez bazy danych. Teraz o samym modelu: co dokładnie agent czyta i zapisuje, kiedy planuje.
Agent domyślnie generuje listę todosów
Poproś agenta o zaplanowanie projektu, a dostaniesz płaską listę czterdziestu punktów w stylu „Implement login”, „Add tests”, „Fix CORS”. Po tygodniu ta lista jest bezużyteczna: nie wiadomo, co od czego zależy, gdzie przebiega granica release'u i skąd w ogóle wziął się punkt 23. Agent nie jest głupi — po prostu nie ma formy, w której mógłby myśleć. Model planowania w My Architect jest właśnie taką formą.
Hierarchia: presety i głębokość
Projekt to drzewo węzłów. Głębokość i nazwy poziomów wyznacza preset: agile daje Epic → Feature → Story → Task, SAFe zaczyna od Initiative (Initiative → Epic → Feature → Story), simple ogranicza się do dwóch poziomów Category → Item, a custom pozwala nazwać poziomy dowolnie. Maksymalna głębokość równa się liczbie poziomów w presecie i serwer tego pilnuje: move_node odrzuci przeniesienie, które wypchnęłoby poddrzewo poza limit (błąd MAX_DEPTH_EXCEEDED).
Przy tworzeniu projektu przez scaffold_project osobno wybiera się złożoność: simple, standard albo complex. Od niej zależy zestaw startowy: dla standard i complex od razu powstają i diagram WBS, i User Story Map.
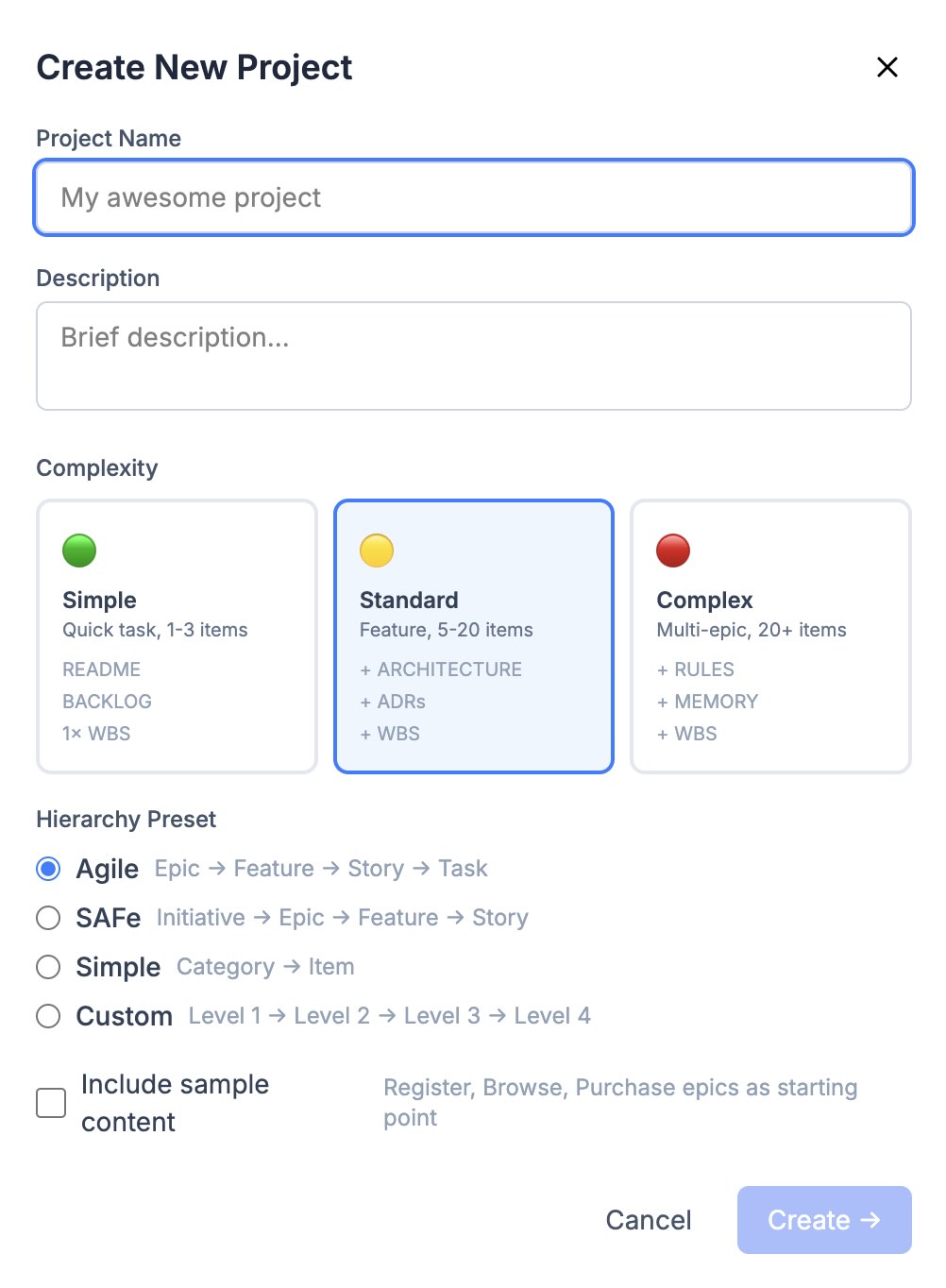
Tworzenie projektu: złożoność określa zestaw startowy, preset — filozofię poziomów: Epic → Feature → Story → Task.
Anatomia węzła
Każdy węzeł ma semantyczny type i liczbowy level — i to celowo dwie różne rzeczy (dlaczego — trochę niżej). Status jest jednym z pięciu: draft, todo, in-progress, done, blocked. Priorytet P1–P3, przypisanie do release'u, wykonawca w assignee (agent albo człowiek). Węzeł nie trzyma treści w sobie, tylko przez referencje: requirementIds dla wymagań, docIds dla dokumentów, diagramIds dla diagramów, plus requires — lista wymagań, które węzeł musi spełnić.
Cztery typy wymagań z typowanymi polami
Decyzje w projekcie zapisuje się jako wymagania czterech typów, a każdy typ ma własne strukturalne pola zamiast wolnego tekstu.
- FR (funkcjonalne):
userStory,acceptanceCriteria,businessValue. - NFR (niefunkcjonalne):
metric,targetValue,measurementMethod. - SAR (decyzja architektoniczna):
rationale,alternatives,consequences. - CON (ograniczenie):
sourceiflexibilityz wartościami fixed albo negotiable.
Identyfikatory generują się automatycznie z licznika per typ: FR-001, NFR-002. Agent wywołuje add_requirement i na dysku pojawia się coś takiego:
id: NFR-003
type: NFR
title: API response time
ownerNodeId: epic-payments
status: approved
fields:
metric: response time p95
targetValue: "< 200 ms"
measurementMethod: load test, 1000 concurrent usersRóżnica względem notatki „API ma być szybkie” polega na tym, że NFR ma sposób weryfikacji. A pole flexibility przy ograniczeniach odpowiada na pytanie, które agenci zwykle rozstrzygają po cichu i błędnie: czy z tym można dyskutować. CON od prawników jest fixed; CON typu „budżet na hosting to 50 dolarów” — negotiable.
Dziedziczenie zamiast kopiowania
Wymaganie należy do dokładnie jednego węzła przez ownerNodeId. Ale widoczne jest dla całego poddrzewa: get_requirements z flagą inherited wspina się po łańcuchu przodków i zbiera wszystko, co wisi wyżej. NFR „p95 poniżej 200 ms” zawieszony na epicu agent dostanie z dowolnego zagnieżdżonego taska, choć fizycznie wymaganie zapisane jest raz.
To rozwiązuje klasyczny problem kopii. Gdyby NFR był duplikowany do każdego taska, to przy zmianie celu z 200 na 150 ms trzeba by znaleźć i poprawić wszystkie kopie — i któraś na pewno zostałaby stara. Tutaj źródło jest jedno, a widoczność wylicza się przy odczycie. Dla powiązania zwrotnego jest tracesTo: wymaganie może wprost wskazywać węzły, które je realizują, i na tym polu budowane jest śledzenie powiązań.
Linter nazw: węzły nazywają byty
Najbardziej kontrowersyjna funkcja według opinii i najbardziej przydatna w praktyce. RFC-013 formułuje regułę tak: nazwa węzła nazywa byt, który powstanie w rezultacie, a nie pracę. „Login system”, nie „Implement login”. Linter odpala się bezpośrednio w build_hierarchy i update_node: drzewo ze złymi nazwami się nie utworzy, a zmianą nazwy reguły też się nie obejdzie.
Co dokładnie jest odrzucane: imperatywy na początku (Add, Create, Build, Implement, Fix i podobne), pipeline'y kroków w stylu „GET → parse → render”, wyliczenia łączone przez „ + ”, listy wariantów a/b/c, wyliczenia po przecinkach, kryteria akceptacji w nawiasach na końcu („(TDD, no regressions)”) i nazwy dłuższe niż dziesięć słów. Każda odmowa wraca do agenta z wyjaśnieniem, gdzie umieścić nadmiar: kroki i akceptację do opisu albo wymagań, wyliczony zakres do węzłów-dzieci.
Agenci bez lintera konsekwentnie serializują do nazwy swój bieżący stan pracy. Linter jest dostrojony na realnym korpusie nazw z produkcji i łapie dokładnie te formy. Efekt widać po miesiącu: backlog z 200 węzłów czyta się jak mapę produktu, z której widać, co system potrafi — a nie jak protokół zleceń, z którego widać tylko, kto co kiedyś robił.
User Story Map jako tekst
Człowiek ma kanwę USM, ale agentowi obrazek nie jest potrzebny. get_usm_view zwraca tę samą mapę jako strukturę: kolumny backbone poziomo, pasy release'ów pionowo. W komórkach leżą karty ze statusami i wykonawcami. Poziom backbone wyznaczany jest automatycznie: brany jest ten, którego węzły mają najwięcej dzieci z przypisanym release'em. Karty bez release'u wpadają do koszyka unplanned, a jego rozmiar to uczciwa metryka tego, ile pracy wciąż nie jest zaplanowane. Dla każdego release'u od razu liczona jest statystyka realizacji (total/done/in-progress).
Przypisywanie węzłów do release'u odbywa się atomowo przez plan_release: wszystkie aktualizacje idą jednym żądaniem bulk, a w odpowiedzi są osobne listy successful i failed, więc częściowa awaria jest widoczna od razu.
Sprytne drobiazgi przy przebudowie drzewa
move_node przenosi węzeł razem z poddrzewem i przelicza poziomy. Ciekawe są szczegóły: typ przeliczany jest tylko dla tych węzłów, których typ przed przeniesieniem odpowiadał ich poziomowi. Story przeniesiona pod epic stanie się feature'em. Ale węzeł, któremu typ ustawiono świadomie wbrew poziomowi, swój typ zachowa — a rozjazd później podświetli validate_project, nie milcząca automatyka. Cykle (przeniesienie pod własnego potomka) są odrzucane z CYCLE_DETECTED jeszcze przed zapisem.
Na przypadek „węzeł leży we właściwym miejscu, ale ma zły typ” jest osobny set_node_type: zmienia się tylko typ semantyczny, a id, slug, pozycja, dzieci i wszystkie referencje zostają na miejscu.
I ostatni drobiazg: numeracja WBS (1.2.3) nie jest nigdzie przechowywana. Wylicza się ją w locie z pozycji wśród siblingów, więc po dowolnym przeniesieniu numeracja pozostaje zwarta i bez dziur.
Co dalej
Model odpowiada na pytanie „jak zbudowany jest plan”. Następna część jest o tym, jak agent według tego planu pracuje: pętla od get_next_task do complete_task, dokumentacja jako część taska i uzgadnianie planu z realnym kodem. My Architect można wypróbować na my-architect.app.