My Architect, часть 3: модель планирования
Это третья статья серии про My Architect. В части 1 я рассказал, зачем агенту память между сессиями, в части 2 — как всё это живёт в YAML-файлах без базы данных. Теперь о самой модели: что именно агент читает и пишет, когда планирует.
Агент по умолчанию генерирует тудушки
Попросите агента распланировать проект, и он выдаст плоский список из сорока пунктов вида «Implement login», «Add tests», «Fix CORS». Через неделю этот список бесполезен: непонятно, что от чего зависит, где граница релиза и почему пункт 23 вообще появился. Агент не глупый, у него просто нет формы, в которую можно думать. Модель планирования в My Architect и есть такая форма.
Иерархия: пресеты и глубина
Проект — дерево узлов. Глубину и имена уровней задаёт пресет: agile даёт Epic → Feature → Story → Task, SAFe начинается с Initiative (Initiative → Epic → Feature → Story), simple ограничивается двумя уровнями Category → Item, а custom позволяет назвать уровни как угодно. Максимальная глубина равна числу уровней в пресете, и сервер это охраняет: move_node отклонит перенос, который вытолкнул бы поддерево за лимит (ошибка MAX_DEPTH_EXCEEDED).
При создании проекта через scaffold_project отдельно выбирается сложность: simple, standard или complex. От неё зависит стартовый набор: для standard и complex сразу создаются и WBS-диаграмма, и User Story Map.
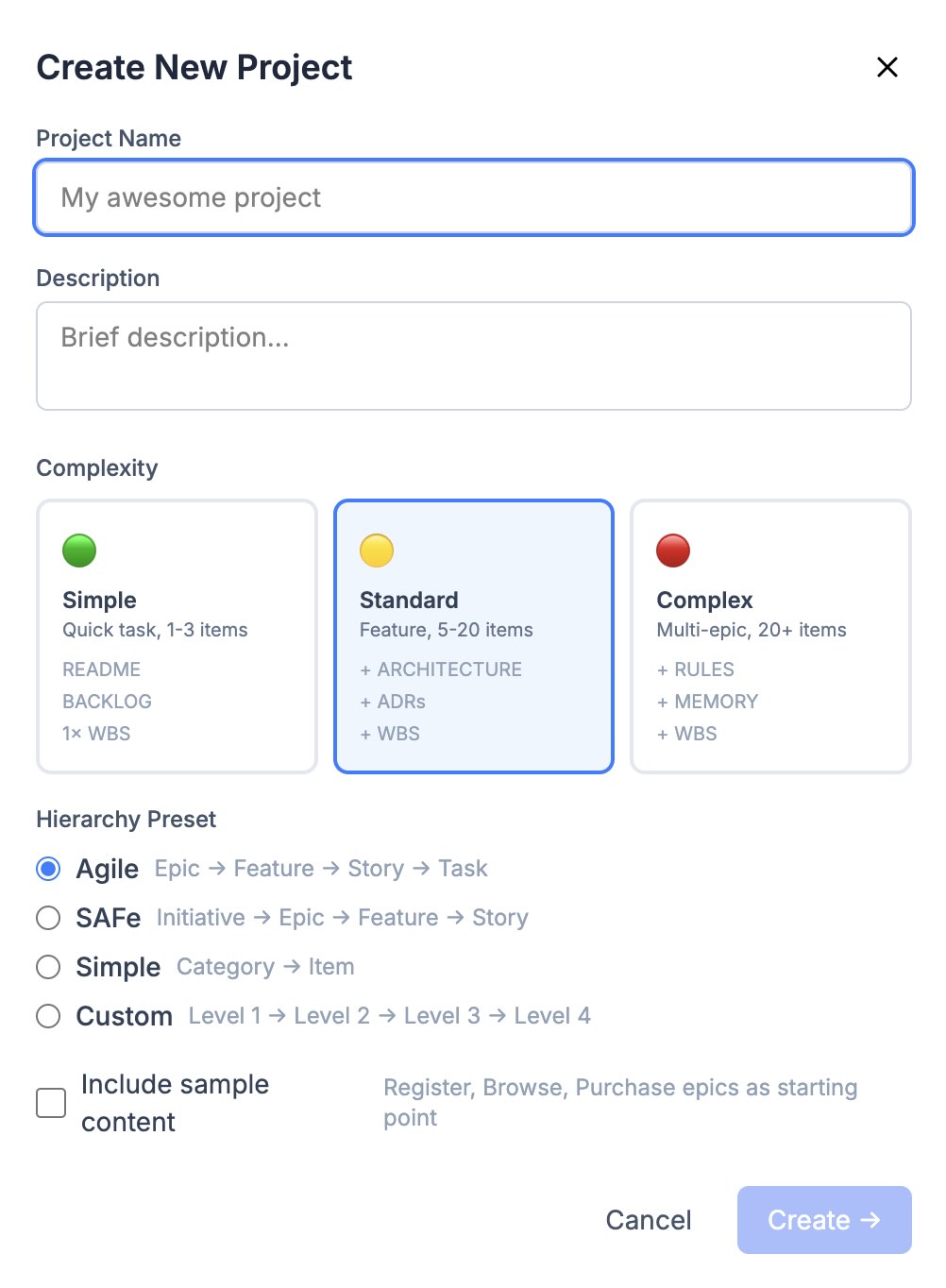
Создание проекта: сложность задаёт стартовый набор, пресет — философию уровней: Epic → Feature → Story → Task.
Анатомия узла
У каждого узла есть семантический type и числовой level, и это намеренно разные вещи (зачем — чуть ниже). Статус один из пяти: draft, todo, in-progress, done, blocked. Приоритет P1–P3, привязка к релизу, исполнитель в assignee (агент или человек). Содержимое узел не хранит внутри себя, а держит по ссылкам: requirementIds для требований, docIds для документов, diagramIds для диаграмм, плюс requires — список требований, которым узел обязан удовлетворять.
Четыре типа требований с типизированными полями
Решения в проекте записываются требованиями четырёх типов, и у каждого типа свои структурные поля, а не общий текст.
- FR (функциональное):
userStory,acceptanceCriteria,businessValue. - NFR (нефункциональное):
metric,targetValue,measurementMethod. - SAR (архитектурное решение):
rationale,alternatives,consequences. - CON (ограничение):
sourceиflexibilityсо значениями fixed или negotiable.
Идентификаторы генерируются автоматически по счётчику типа: FR-001, NFR-002. Агент вызывает add_requirement, и на диске появляется примерно такое:
id: NFR-003
type: NFR
title: API response time
ownerNodeId: epic-payments
status: approved
fields:
metric: response time p95
targetValue: "< 200 ms"
measurementMethod: load test, 1000 concurrent usersРазница с заметкой «API должен быть быстрым» в том, что у NFR есть способ проверки. А поле flexibility у ограничений отвечает на вопрос, который агенты обычно решают молча и неправильно: можно ли с этим спорить. CON от юристов — fixed, CON «бюджет на хостинг 50 долларов» — negotiable.
Наследование вместо копирования
Требование принадлежит ровно одному узлу через ownerNodeId. Но видно оно всему поддереву: get_requirements с флагом inherited поднимается по цепочке предков и собирает всё, что висит выше. NFR «p95 меньше 200 мс», повешенный на эпик, агент получит из любой вложенной задачи, хотя физически требование записано один раз.
Это решает классическую проблему копий. Если бы NFR дублировался в каждую задачу, то при изменении цели с 200 до 150 мс пришлось бы найти и поправить все копии, и какая-нибудь обязательно осталась бы старой. Здесь источник один, а видимость вычисляется при чтении. Для обратной связи есть tracesTo: требование может явно указывать узлы, которые его реализуют, и по этому полю строится трассировка.
Линтер названий: узлы называют сущности
Самая спорная фича по отзывам и самая полезная по факту. RFC-013 формулирует правило так: название узла именует сущность, которая появится в результате, а не работу. «Login system», не «Implement login». Линтер срабатывает прямо в build_hierarchy и update_node: дерево с плохими названиями не создастся, переименованием правило тоже не обойти.
Что именно заворачивается: императивы в начале (Add, Create, Build, Implement, Fix и подобные), пайплайны шагов вида «GET → parse → render», перечисления через « + », списки вариантов a/b/c, перечисления через запятые, приёмочные критерии в скобках в конце («(TDD, no regressions)») и названия длиннее десяти слов. Каждый отказ приходит агенту с объяснением, куда деть лишнее: шаги и приёмку в описание или требования, перечисленный объём в дочерние узлы.
Агенты без линтера стабильно сериализуют в название своё текущее состояние работы. Линтер настроен на реальном корпусе названий из продакшена и ловит именно эти формы. Результат заметен через месяц: бэклог из 200 узлов читается как карта продукта, по которой видно, что система умеет, а не как протокол поручений, по которому видно лишь, кто что когда-то делал.
User Story Map текстом
Канва с USM есть у человека, но агенту картинка не нужна. get_usm_view отдаёт ту же карту структурой: колонки backbone по горизонтали, полосы релизов по вертикали. В ячейках лежат карточки со статусами и исполнителями. Уровень backbone определяется автоматически: берётся тот, у чьих узлов больше всего детей с назначенным релизом. Карточки без релиза падают в корзину unplanned, и её размер — честная метрика того, сколько работы ещё не распланировано. По каждому релизу сразу считается статистика выполнения (total/done/in-progress).
Назначение узлов в релиз делается атомарно через plan_release: все обновления уходят одним bulk-запросом, а в ответе раздельные списки successful и failed, так что частичный сбой виден сразу.
Умные мелочи при перестройке дерева
move_node переносит узел вместе с поддеревом и пересчитывает уровни. Интересное в деталях: тип пересчитывается только у тех узлов, чей тип до переноса соответствовал их уровню. Story, переехавшая под эпик, станет feature. А узел, которому тип выставили осознанно вразрез с уровнем, свой тип сохранит, и расхождение потом подсветит validate_project, а не молчаливая автоматика. Циклы (перенос под собственного потомка) отклоняются с CYCLE_DETECTED ещё до записи.
Для случая «узел лежит правильно, но назван не тем типом» есть отдельный set_node_type: меняется только семантический тип, а id, slug, позиция, дети и все ссылки остаются на месте.
И последняя мелочь: WBS-нумерация (1.2.3) нигде не хранится. Она вычисляется из позиции среди siblings на лету, поэтому после любого переноса нумерация остаётся плотной и без дыр.
Что дальше
Модель отвечает на вопрос «как устроен план». Следующая часть — про то, как агент по этому плану работает: цикл от get_next_task до complete_task, документация как часть задачи и сверка плана с реальным кодом. Попробовать My Architect можно на my-architect.app.