Сториборд до видео: вижу весь ролик заранее — и правлю сценарий, пока это дёшево
Самое дешёвое место починить ролик — пока он ещё не ролик. Раньше я этого не понимал: гнал идею в видео почти напрямую. Сгенерю минуту дорогого видео — и только там вижу, что сцена не читается. Дальше переделка, время, деньги. Теперь между сценаристом и видеомоделью у меня стоит ещё один слой — раскадровка. Он всё и поменял.
В первой части я выбирал сценариста — вызов LLM, который из идеи в одну строку собирает шот-лист на каждую сцену. Во второй — видеомодель, которая этот шот-лист оживляет. Между ними был провал: сценарист отдаёт текст, видеомодель сразу рисует финальное видео, а весь высокоуровневый ролик в голове я не вижу — только отдельные описания кадров. Раскадровка этот провал закрыла.
Что это за слой
Раскадровка — это карандашный сториборд по шот-листу: те же сцены, но нарисованные. Не финальное видео, а быстрый чёрно-белый набросок: что в кадре, кто говорит, куда движется. Одна картинка на весь ролик. Я смотрю на неё — и впервые вижу свою идею целиком, до того как потратил хоть секунду генерации видео.
Звучит как мелочь. На деле это разница между «надеюсь, получится» и «вижу, что получится».
Как это эволюционировало
Сразу так не заработало. Сториборд прошёл четыре стадии, и каждая добавляла то, чего мне не хватало, чтобы «увидеть» ролик.
Стадия 1. Только ключевые кадры
Сначала я просил по одному кадру на сцену — стартовую позу. Получал аккуратные картинки и почти ничего не понимал. Персонаж есть, движения нет. Куда он идёт, что делает, чем сцена заканчивается — непонятно.

Три сцены, по одному кадру. Видно героя и обстановку, но ритма ролика не видно.
Стадия 2. Движение: START → PEAK
Тогда я разбил каждую сцену на два кадра — начало (START) и пик (PEAK) — и поставил между ними стрелку. Сразу стало читаться движение: робот сидит → робот заглядывает в кружку. Баллоны я пока оставил пустыми, как заготовки: место под реплику уже видно, текста ещё нет.
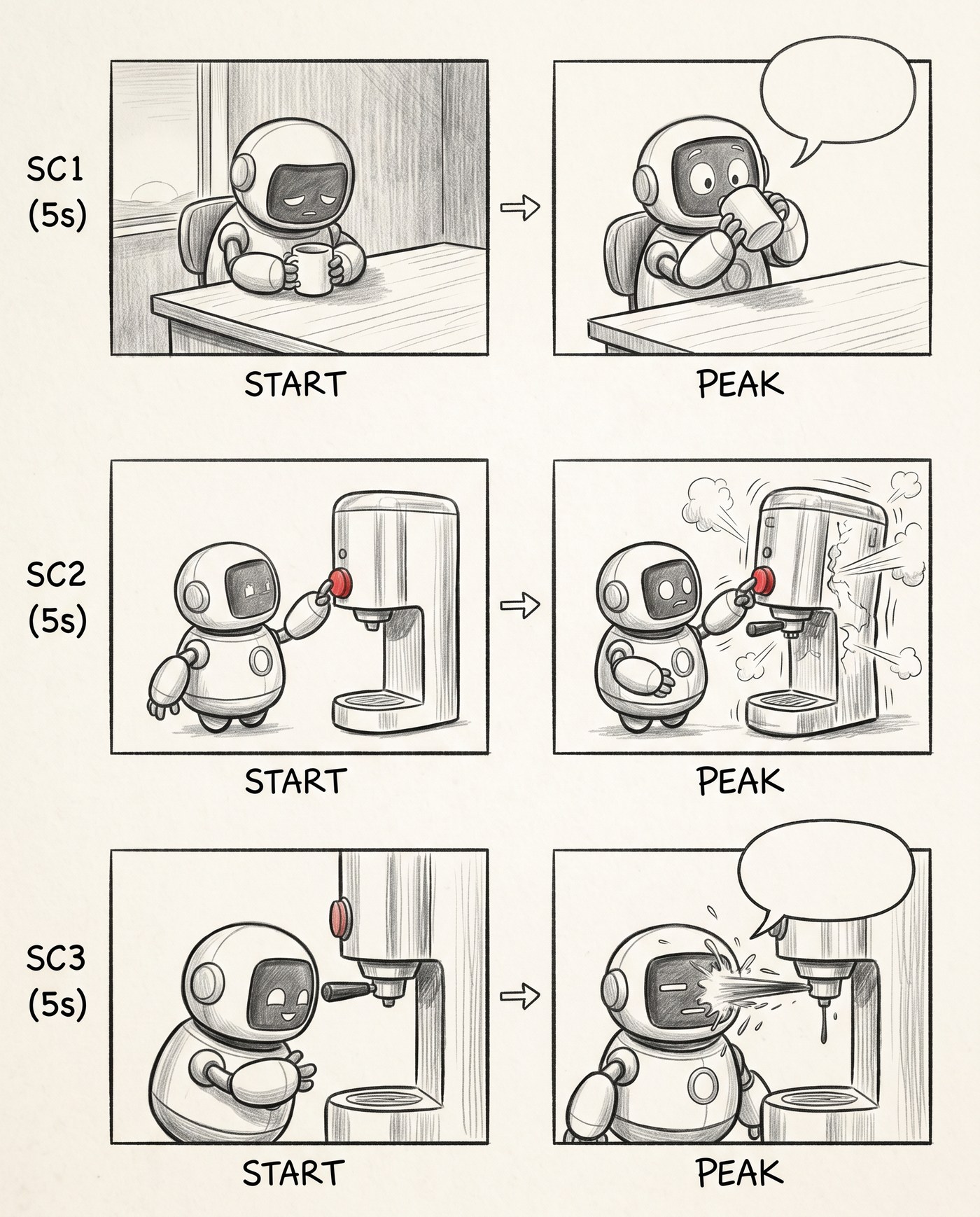
Внутри сцены появилось движение. Пустые баллоны — места под реплики.
Стадия 3. Реплики на местах
Дальше я попросил вписать точные реплики — те самые, что выдал сценарист. «Empty... again?!», подпись-нарратор «It had waited all night for this.», финальное «...worth it.». Вот тут ролик впервые зазвучал в голове: читаю сториборд слева направо, сверху вниз — и проигрываю всю сцену с диалогом. Слабую реплику или провисший бит теперь видно глазами, а не угадываешь.
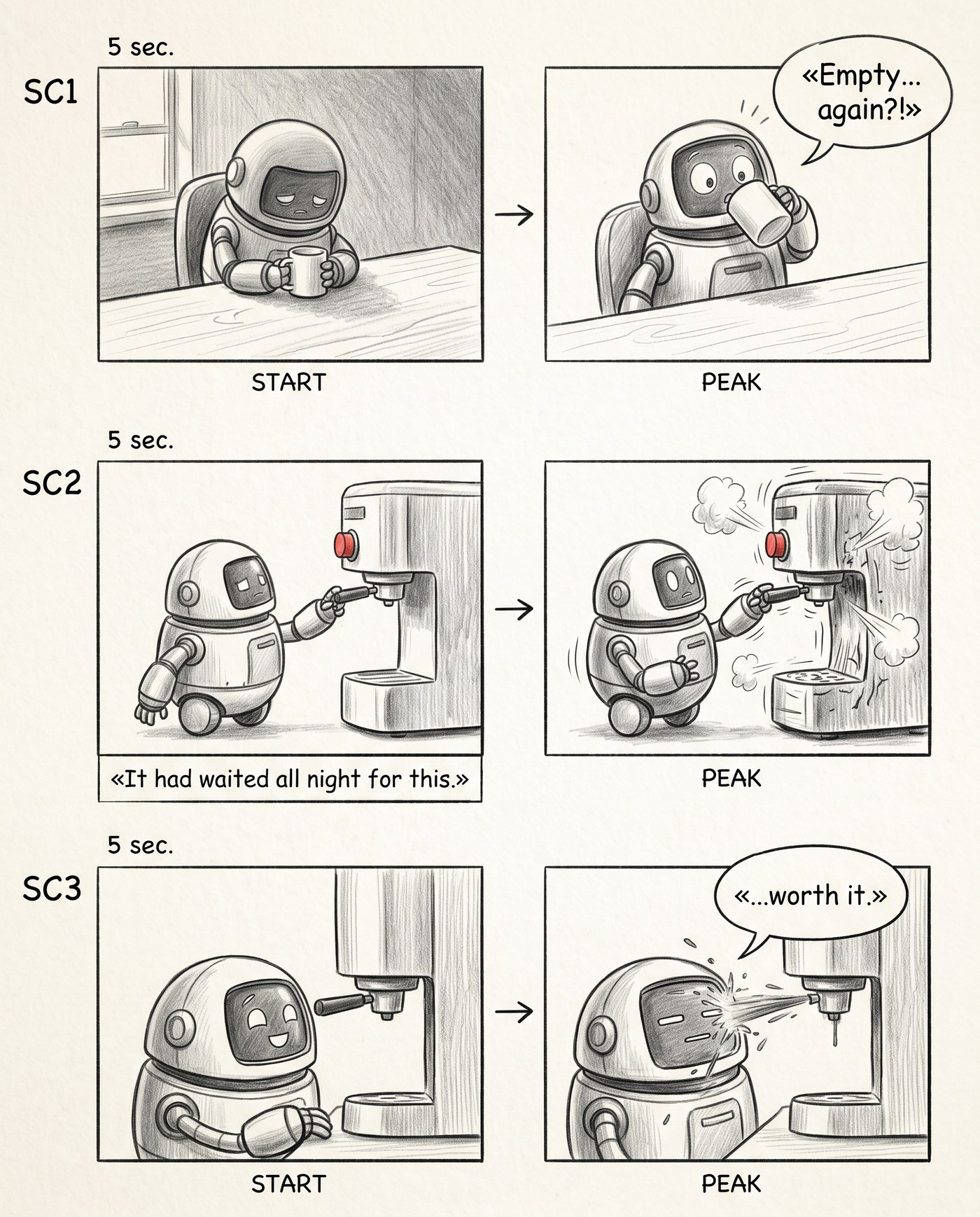
Реплики из шот-листа на местах. Ролик читается целиком — со звуком в голове.
Стадия 4. Каст
Последнее, чего не хватало, — управляемый каст. Один герой ещё ладно, но как только в кадре двое, модель начинает их путать: то кот рыжий, то серый, то вообще другой. Я добавил в промпт второго персонажа и узкую полосу CASTING справа — мини-портреты героев. А чтобы они не плыли от кадра к кадру, дал модели референсы на вход:

Вход каста: два референса. По ним модель держит внешность героев во всех кадрах.
Результат — сториборд, где робот и кот узнаваемы от первого кадра до последнего, а сбоку висит «каст», как в настоящей пре-продакшн-раскадровке.
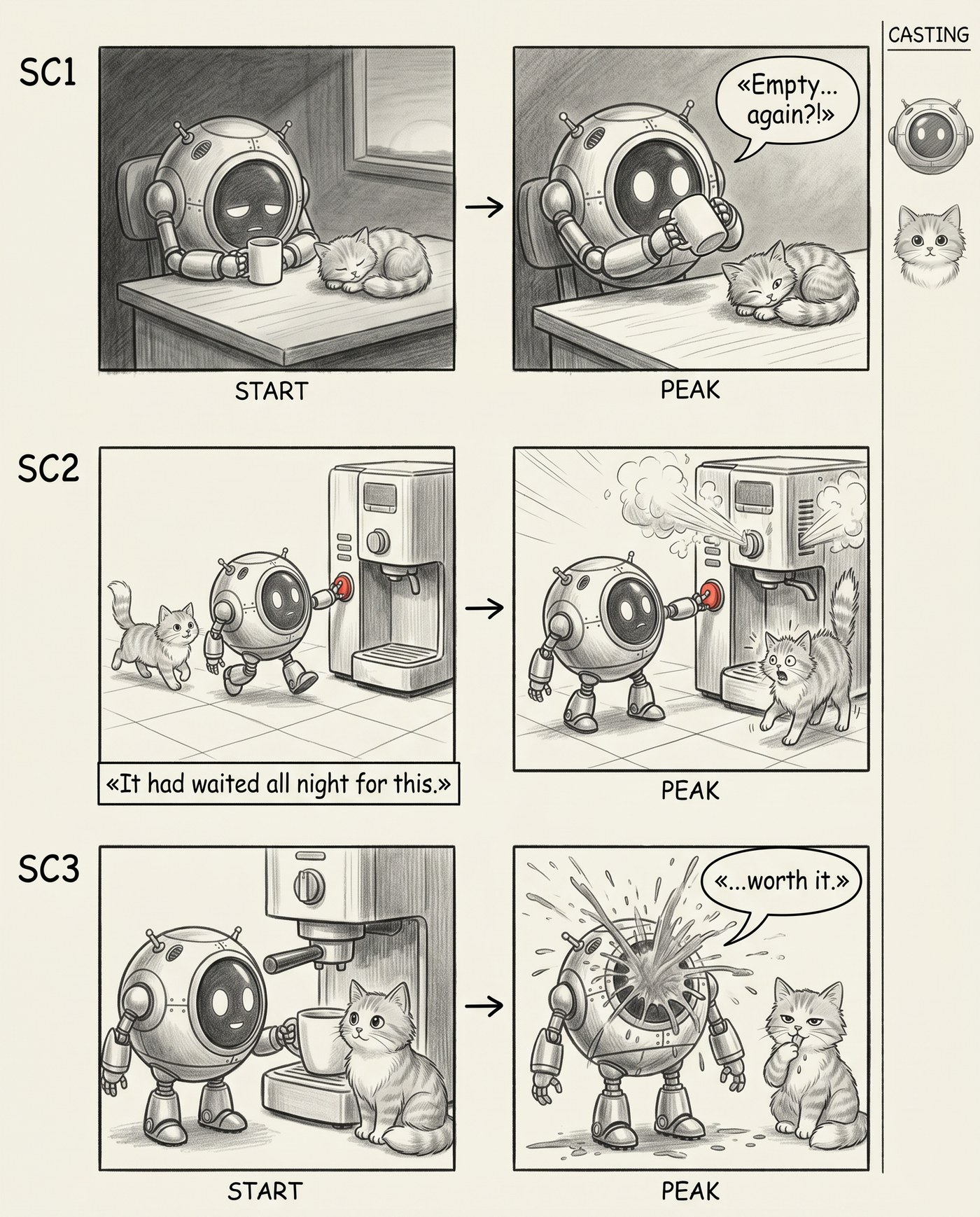
Двое героев, оба стабильны между кадрами, и полоса CASTING справа.
Зачем мне это
Я теперь вижу весь высокоуровневый ролик до генерации видео. И это даёт одно, но большое: я правлю сценарий, пока это дёшево.
Что я ловлю на сториборде:
- пустой бит — сцена есть, а внутри ничего не происходит;
- не ту реплику — текст плоский или говорит не тот персонаж;
- потерю героя — кто-то выпал из кадра на самом важном моменте;
- сбитый каст — персонаж «поплыл» внешне.
Любую из этих штук на готовом видео я чинил бы перегенерацией — это время и деньги. На сториборде я меняю строку в шот-листе и пересобираю картинку за копейки. Это мой дешёвый предпросмотр всего ролика и точка, где сценарий ещё пластичный.
Промпты
Весь сториборд держится на одном промпте к image-модели. Вот база — вариант без каста, один герой (переносы строк добавил для читаемости, текст промпта дословный):
Hand-drawn graphite pencil storyboard, monochrome grayscale,
professional film pre-production look, soft pencil shading on
off-white paper. NO color.
Draw a speech balloon or a narrator caption box ONLY on panels
explicitly marked below; where text is specified, render that EXACT
text accurately and legibly. A speech balloon is rounded with a tail
to a character; a narrator caption box is a plain rectangle along the
panel bottom, never attached to a character.
LAYOUT: 3 horizontal rows stacked top-to-bottom, ONE ROW PER SCENE.
Put ONLY the scene number (SC1, SC2, …) in the left margin of each row.
Inside each row draw the panels left-to-right at equal size, with a
small hand-drawn arrow pointing from each panel to the next so the
motion reads as a left-to-right progression. Beneath each panel write
its phase word EXACTLY ONCE: only START under the left panel and PEAK
under the right panel. Do NOT write any other words, numbers or labels
on or inside the panels. Keep every character visually consistent
across all panels.
SC1 (5s): START — a small round robot sits slumped at a wooden desk at
dawn, holding an empty white mug, its screen-face dim; PEAK — it lifts
the mug and peers inside, two wide surprised eyes lighting up. On the
PEAK panel draw a speech balloon with a tail to the character: «Empty...
again?!».
SC2 (5s): START — the robot rolls up to a tall chrome coffee machine,
reaching for a big red button; PEAK — it jabs the button, the machine
shudders and rattles, steam bursting from its seams. On the START panel
draw a narrator caption box along the bottom edge (a plain rectangle,
not a speech balloon): «It had waited all night for this.».
SC3 (5s): START — the robot leans in close to the machine's spout,
screen-face hopeful; PEAK — a jet of coffee sprays it full in the face,
its screen-face freezing into a flat line. On the PEAK panel draw a
speech balloon with a tail to the character: «...worth it.».Что здесь делает работу:
- грейскейл и «NO color» — это пре-продакшн-набросок, цвет тут только мешает;
- LAYOUT — жёстко задаёт сетку: ряд на сцену, два кадра, стрелка, подписи START/PEAK и больше никаких лишних надписей;
- balloon vs caption box — реплика героя рисуется облачком с хвостиком, закадровый текст — плашкой снизу; модель не должна их путать;
- точный текст в «ёлочках» — реплики прошу вписать дословно, в кавычках-ёлочках, чтобы потом сверять с шот-листом глазами.
Чтобы добавить второго героя, я дописал к тому же промпту каст. В шапку — что персонажей теперь двое и оба должны оставаться узнаваемыми. В каждую сцену добавил действия кота: спит на столе, трусит рядом, сидит и смотрит. А справа — полоса CASTING с референсами:
There are two recurring characters, a small round robot and a fluffy
cat; keep BOTH visually consistent across every panel.
On the right edge, a narrow vertical CASTING strip separated by a thin
line, with a small reference headshot of each main character drawn in
the same graphite pencil style; use the attached reference images for
the characters' appearance.Дальше — что из этого получается у разных моделей.
Бонус: чем рисовать сториборд
Один и тот же сториборд я прогнал через четыре image-модели в двух вариантах промпта: без каста (один робот) и с кастом (робот, кот и полоса CASTING). Требования для всех одинаковые — грейскейл, точные реплики, сетка START→PEAK. Смотрел на четыре вещи: следует ли модель инструкциям (грейскейл, нарратив), держит ли точный текст, не плывёт ли каст между кадрами и насколько живой рисунок.
Без каста: один герой

Nano Banana Pro: чистая сетка, движение читается, текст на месте.

GPT Image 2: самая богатая графика — фактура карандаша, фон, детали. Реплики только без ёлочек.

Seedream 4.5: рисунок симпатичный, но кнопка — красная. Промпт просил грейскейл и «NO color» — модель это нарушила.
С кастом: робот и кот
Здесь сложнее: двое героев, их надо держать одинаковыми во всех кадрах, плюс отрисовать полосу CASTING по референсам.

Nano Banana 2: оба героя стабильны, каст на месте, реплики дословно с ёлочками. На этой модели я сейчас и работаю.

GPT Image 2: детализация лучшая из всех — но реплики снова без ёлочек, и кадр заметно плотнее.

Nano Banana Pro: чисто и аккуратно, каст держит. По моему опыту — медленнее и дороже остальных.
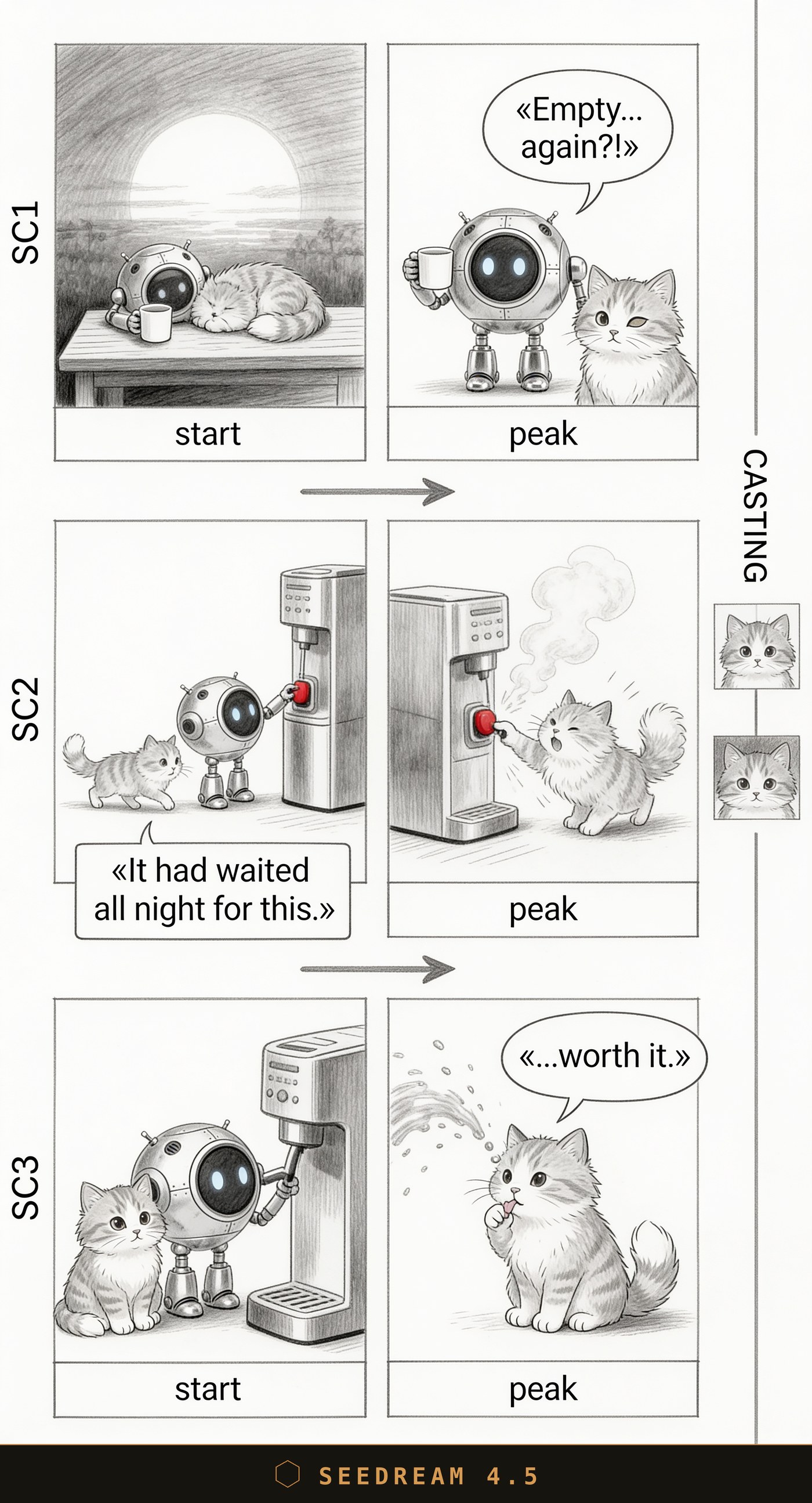
Seedream 4.5: а вот тут критическая ошибка. На финальном кадре робот вообще пропал, а его реплику «...worth it.» отдали коту. Шутка про облитого кофе робота сломана — главного героя в панчлайне нет.
Короткий итог
| Модель | Сильное | Слабое | Где у меня |
|---|---|---|---|
| Nano Banana 2 | Стабильный каст, дословный текст с ёлочками, чистая раскадровка | — | Рабочий выбор сейчас |
| GPT Image 2 | Лучшая детализация и фактура | Реплики без ёлочек, кадр плотнее | Порекомендую, если выйдет дешевле Nano Banana 2 |
| Nano Banana Pro | Чисто, каст держит | По опыту медленнее и дороже | Запас, когда не жалко времени |
| Seedream 4.5 | Приятный «скетчевый» стиль | Критические ошибки: красная кнопка вместо грейскейла, теряет героя и отдаёт реплику не тому | Мимо — ошибки ломают сцену |
Вывод простой. Для раскадровки мне важнее всего, чтобы модель ровно делала, что просят: держала грейскейл, точный текст и каст. По этому критерию Nano Banana 2 у меня сейчас в проде — она не ошибается на главном. GPT Image 2 рисует красивее всех, и если окажется дешевле, я порекомендую её за детализацию. Nano Banana Pro — крепкий запас, но медленнее и дороже. Seedream 4.5 отложил: стиль приятный, но критические ошибки на сцене мне дороже красоты.
Что в итоге получилось
Раскадровку я проверил, пару реплик в сценарии поправил — и отдал сцену видеомодели. Той самой Seedance 2.0, на которой остановился во второй части. Вот результат: тот же робот, тот же кот, те же биты — только уже в цвете и со звуком.
От серого карандашного плана до готового кадра. Сценарий я согласовал ещё на сториборде — видеомодели осталось отрисовать.
Где это в серии
Сложилась цепочка. В первой части я выбирал сценариста — он задаёт потолок качества текста. Во второй — видеомодель, она его исполняет. Раскадровка встала между ними: слой, где я наконец вижу весь ролик заранее и могу его поправить, пока правка стоит копейки. Раньше я доверял пайплайну вслепую. Теперь смотрю и решаю.