Сторіборд до відео: бачу весь ролик заздалегідь — і правлю сценарій, поки це дешево
Найдешевше місце полагодити ролик — поки він ще не ролик. Раніше я цього не розумів: гнав ідею у відео майже навпростець. Згенерую хвилину дорогого відео — і лише там бачу, що сцена не читається. Далі переробка, час, гроші. Тепер між сценаристом і відеомоделлю в мене стоїть іще один шар — розкадровка. Він усе й змінив.
У першій частині я обирав сценариста — виклик LLM, який з ідеї в один рядок збирає шот-лист на кожну сцену. У другій — відеомодель, яка цей шот-лист оживляє. Між ними був провал: сценарист віддає текст, відеомодель одразу малює фінальне відео, а весь високорівневий ролик у голові я не бачу — лише окремі описи кадрів. Розкадровка цей провал закрила.
Що це за шар
Розкадровка — це олівцевий сторіборд за шот-листом: ті самі сцени, але намальовані. Не фінальне відео, а швидкий чорно-білий накид: що в кадрі, хто говорить, куди рухається. Одна картинка на весь ролик. Я дивлюся на неї — і вперше бачу свою ідею цілком, до того як витратив бодай секунду генерації відео.
Звучить як дрібниця. Насправді це різниця між «сподіваюся, вийде» і «бачу, що вийде».
Як це еволюціонувало
Одразу так не запрацювало. Сторіборд пройшов чотири стадії, і кожна додавала те, чого мені бракувало, щоб «побачити» ролик.
Стадія 1. Тільки ключові кадри
Спершу я просив по одному кадру на сцену — стартову позу. Отримував охайні картинки і майже нічого не розумів. Персонаж є, руху немає. Куди він іде, що робить, чим сцена закінчується — незрозуміло.

Три сцени, по одному кадру. Видно героя й оточення, але ритму ролика не видно.
Стадія 2. Рух: START → PEAK
Тоді я розбив кожну сцену на два кадри — початок (START) і пік (PEAK) — і поставив між ними стрілку. Одразу почав читатися рух: робот сидить → робот зазирає в кухоль. Балони я поки лишив порожніми, як заготовки: місце під репліку вже видно, тексту ще немає.
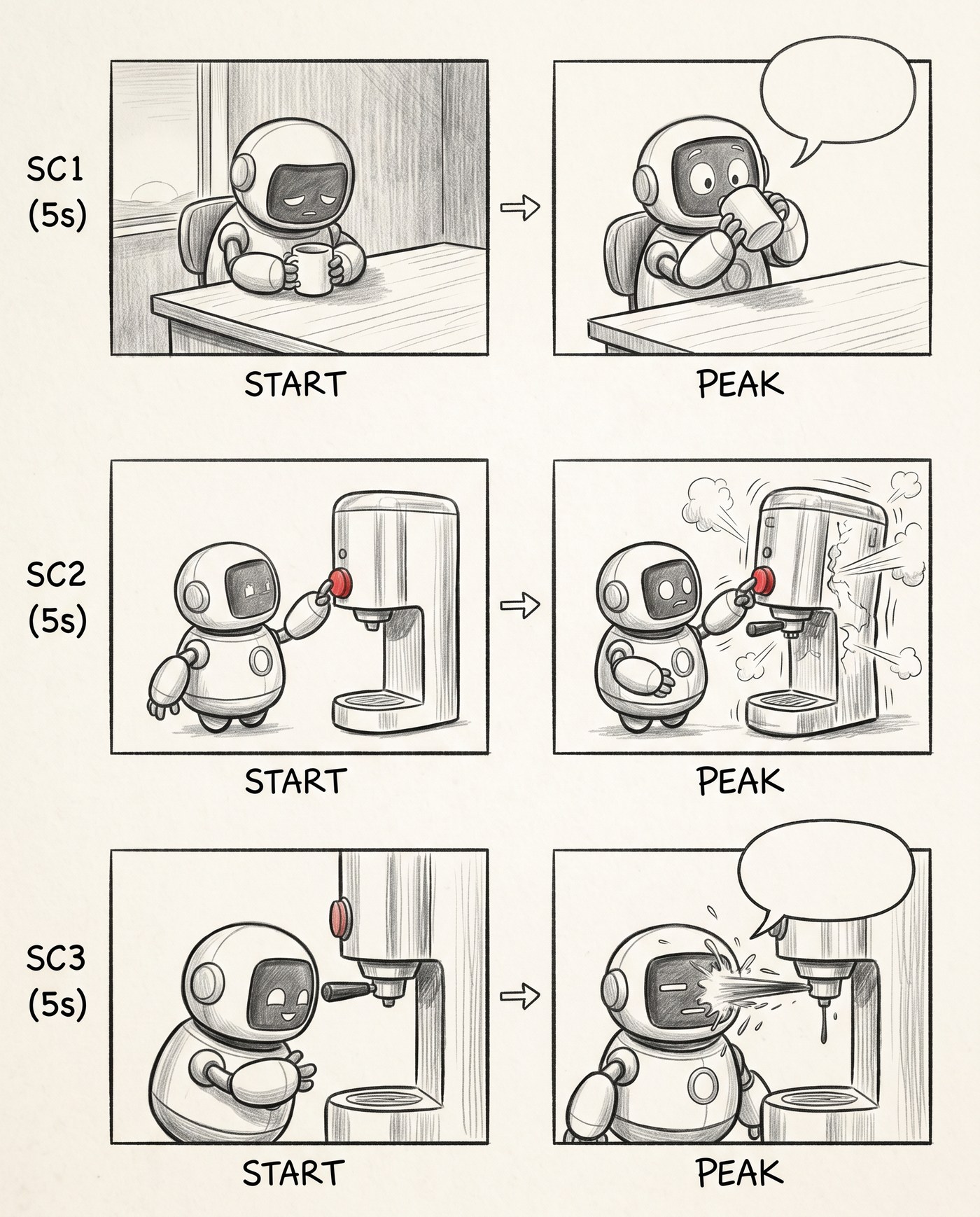
Усередині сцени з'явився рух. Порожні балони — місця під репліки.
Стадія 3. Репліки на місцях
Далі я попросив вписати точні репліки — ті самі, що видав сценарист. «Empty... again?!», підпис-наратор «It had waited all night for this.», фінальне «...worth it.». Ось тут ролик уперше зазвучав у голові: читаю сторіборд зліва направо, згори вниз — і програю всю сцену з діалогом. Слабку репліку чи провислий біт тепер видно очима, а не вгадуєш.
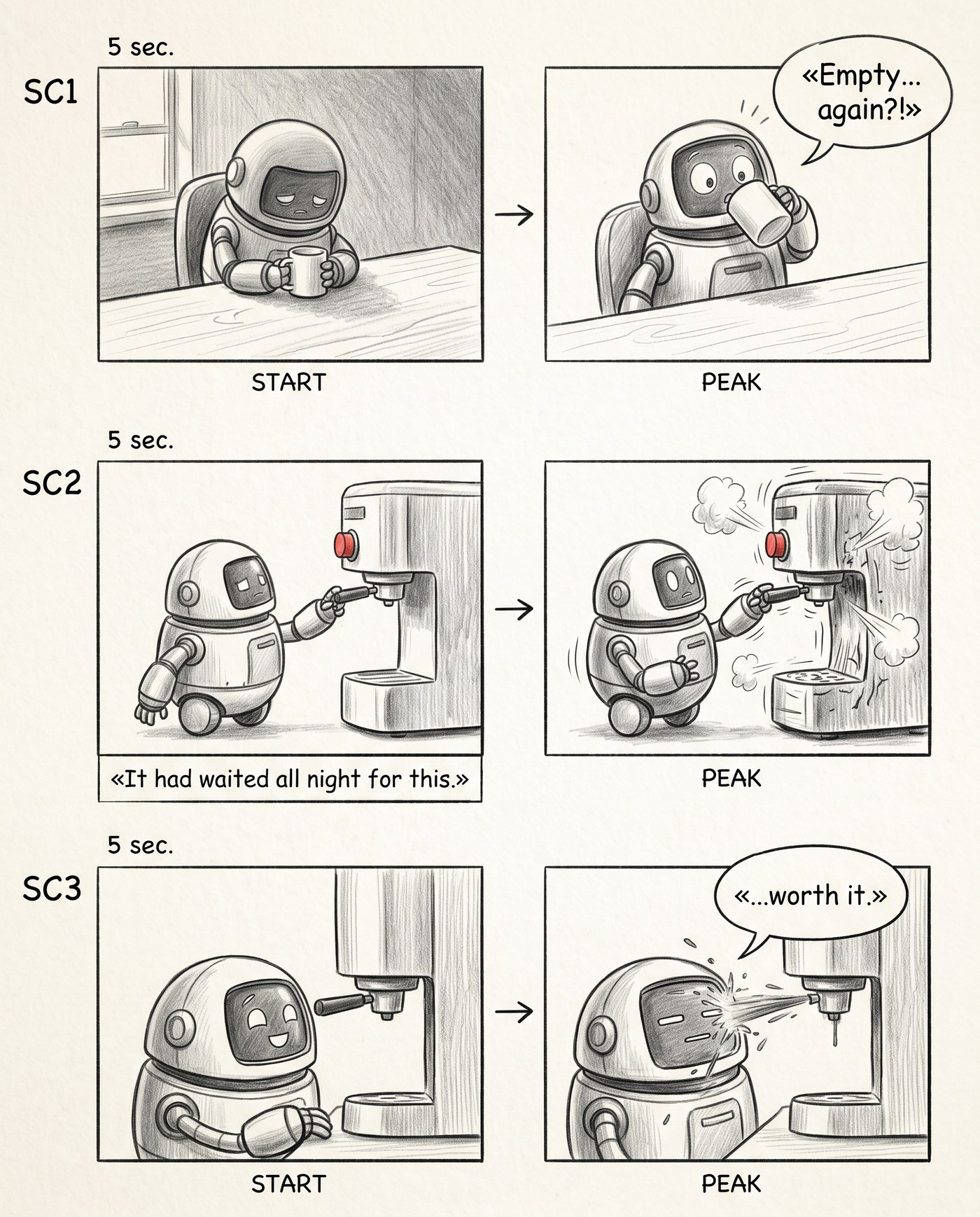
Репліки з шот-листа на місцях. Ролик читається цілком — зі звуком у голові.
Стадія 4. Каст
Останнє, чого бракувало, — керований каст. Один герой ще нічого, та щойно в кадрі двоє, модель починає їх плутати: то кіт рудий, то сірий, то взагалі інший. Я додав у промпт другого персонажа і вузьку смугу CASTING праворуч — міні-портрети героїв. А щоб вони не пливли від кадру до кадру, дав моделі референси на вхід:

Вхід каста: два референси. За ними модель тримає зовнішність героїв у всіх кадрах.
Результат — сторіборд, де робот і кіт упізнавані від першого кадру до останнього, а збоку висить «каст», як у справжній препродакшн-розкадровці.
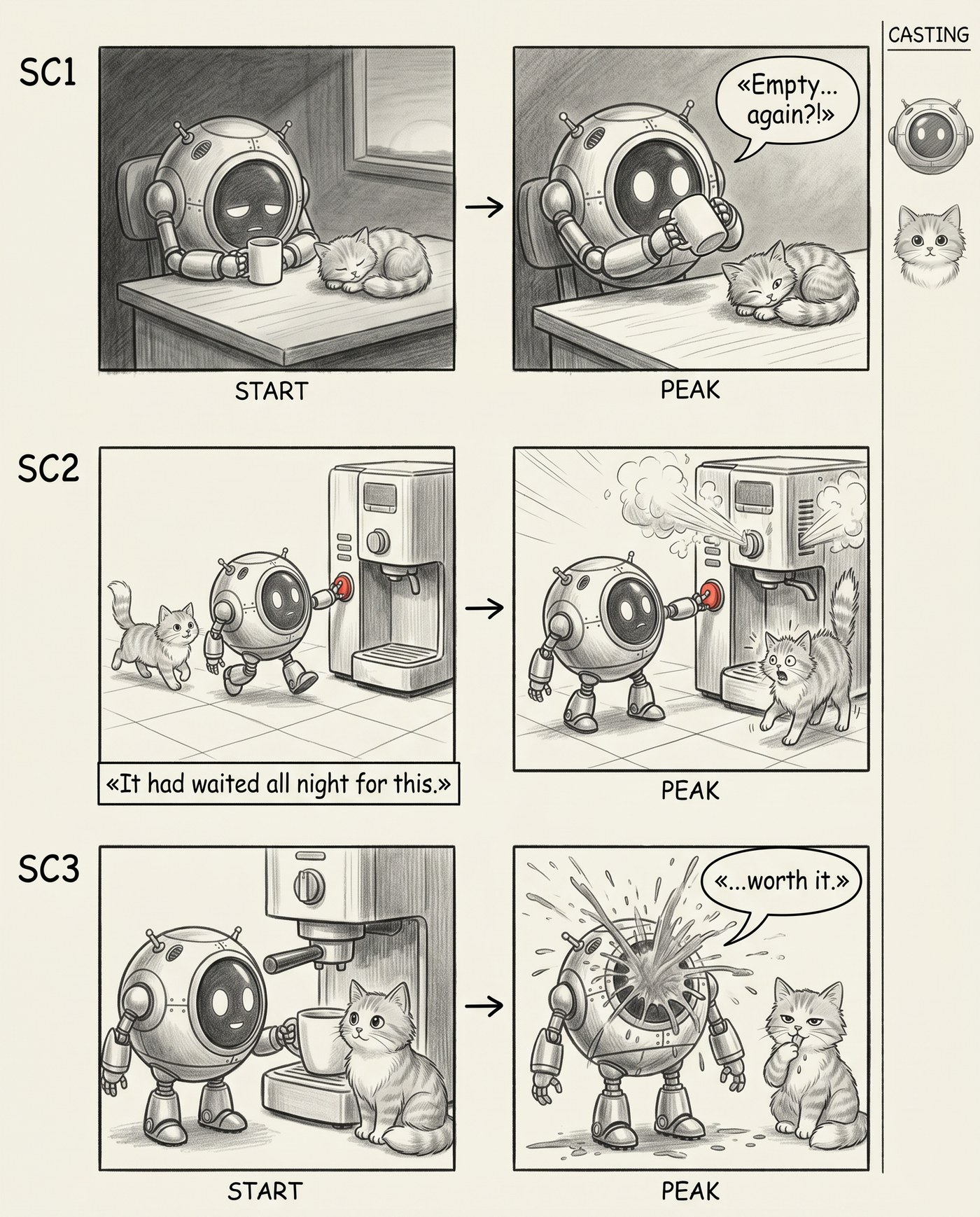
Двоє героїв, обидва стабільні між кадрами, і смуга CASTING праворуч.
Навіщо мені це
Я тепер бачу весь високорівневий ролик до генерації відео. І це дає одне, але велике: я правлю сценарій, поки це дешево.
Що я ловлю на сторіборді:
- порожній біт — сцена є, а всередині нічого не відбувається;
- не ту репліку — текст плаский або говорить не той персонаж;
- втрату героя — хтось випав із кадру в найважливіший момент;
- збитий каст — персонаж «поплив» зовні.
Будь-яку з цих штук на готовому відео я лагодив би перегенерацією — це час і гроші. На сторіборді я міняю рядок у шот-листі й перезбираю картинку за копійки. Це мій дешевий передперегляд усього ролика і точка, де сценарій ще пластичний.
Промпти
Весь сторіборд тримається на одному промпті до image-моделі. Ось база — варіант без каста, один герой (переноси рядків додав для читабельності, текст промпта дослівний):
Hand-drawn graphite pencil storyboard, monochrome grayscale,
professional film pre-production look, soft pencil shading on
off-white paper. NO color.
Draw a speech balloon or a narrator caption box ONLY on panels
explicitly marked below; where text is specified, render that EXACT
text accurately and legibly. A speech balloon is rounded with a tail
to a character; a narrator caption box is a plain rectangle along the
panel bottom, never attached to a character.
LAYOUT: 3 horizontal rows stacked top-to-bottom, ONE ROW PER SCENE.
Put ONLY the scene number (SC1, SC2, …) in the left margin of each row.
Inside each row draw the panels left-to-right at equal size, with a
small hand-drawn arrow pointing from each panel to the next so the
motion reads as a left-to-right progression. Beneath each panel write
its phase word EXACTLY ONCE: only START under the left panel and PEAK
under the right panel. Do NOT write any other words, numbers or labels
on or inside the panels. Keep every character visually consistent
across all panels.
SC1 (5s): START — a small round robot sits slumped at a wooden desk at
dawn, holding an empty white mug, its screen-face dim; PEAK — it lifts
the mug and peers inside, two wide surprised eyes lighting up. On the
PEAK panel draw a speech balloon with a tail to the character: «Empty...
again?!».
SC2 (5s): START — the robot rolls up to a tall chrome coffee machine,
reaching for a big red button; PEAK — it jabs the button, the machine
shudders and rattles, steam bursting from its seams. On the START panel
draw a narrator caption box along the bottom edge (a plain rectangle,
not a speech balloon): «It had waited all night for this.».
SC3 (5s): START — the robot leans in close to the machine's spout,
screen-face hopeful; PEAK — a jet of coffee sprays it full in the face,
its screen-face freezing into a flat line. On the PEAK panel draw a
speech balloon with a tail to the character: «...worth it.».Що тут робить роботу:
- грейскейл і «NO color» — це препродакшн-накид, колір тут тільки заважає;
- LAYOUT — жорстко задає сітку: ряд на сцену, два кадри, стрілка, підписи START/PEAK і жодних зайвих написів;
- balloon vs caption box — репліка героя малюється хмаринкою з хвостиком, закадровий текст — плашкою знизу; модель не повинна їх плутати;
- точний текст у «ялинках» — репліки прошу вписати дослівно, у лапках-ялинках, щоб потім звіряти з шот-листом очима.
Щоб додати другого героя, я дописав до того ж промпта каст. У шапку — що персонажів тепер двоє і обидва мають лишатися впізнаваними. У кожну сцену додав дії кота: спить на столі, дріботить поруч, сидить і дивиться. А праворуч — смуга CASTING з референсами:
There are two recurring characters, a small round robot and a fluffy
cat; keep BOTH visually consistent across every panel.
On the right edge, a narrow vertical CASTING strip separated by a thin
line, with a small reference headshot of each main character drawn in
the same graphite pencil style; use the attached reference images for
the characters' appearance.Далі — що з цього виходить у різних моделей.
Бонус: чим малювати сторіборд
Один і той самий сторіборд я прогнав через чотири image-моделі у двох варіантах промпта: без каста (один робот) і з кастом (робот, кіт і смуга CASTING). Вимоги для всіх однакові — грейскейл, точні репліки, сітка START→PEAK. Дивився на чотири речі: чи дотримується модель інструкцій (грейскейл, наратив), чи тримає точний текст, чи не пливе каст між кадрами і наскільки живий малюнок.
Без каста: один герой

Nano Banana Pro: чиста сітка, рух читається, текст на місці.

GPT Image 2: найбагатша графіка — фактура олівця, фон, деталі. Репліки лише без ялинок.

Seedream 4.5: малюнок симпатичний, але кнопка — червона. Промпт просив грейскейл і «NO color» — модель це порушила.
З кастом: робот і кіт
Тут складніше: двоє героїв, їх треба тримати однаковими в усіх кадрах, плюс відмалювати смугу CASTING за референсами.

Nano Banana 2: обидва герої стабільні, каст на місці, репліки дослівно з ялинками. На цій моделі я зараз і працюю.

GPT Image 2: деталізація найкраща з усіх — але репліки знову без ялинок, і кадр помітно щільніший.

Nano Banana Pro: чисто й охайно, каст тримає. З мого досвіду — повільніше й дорожче за решту.
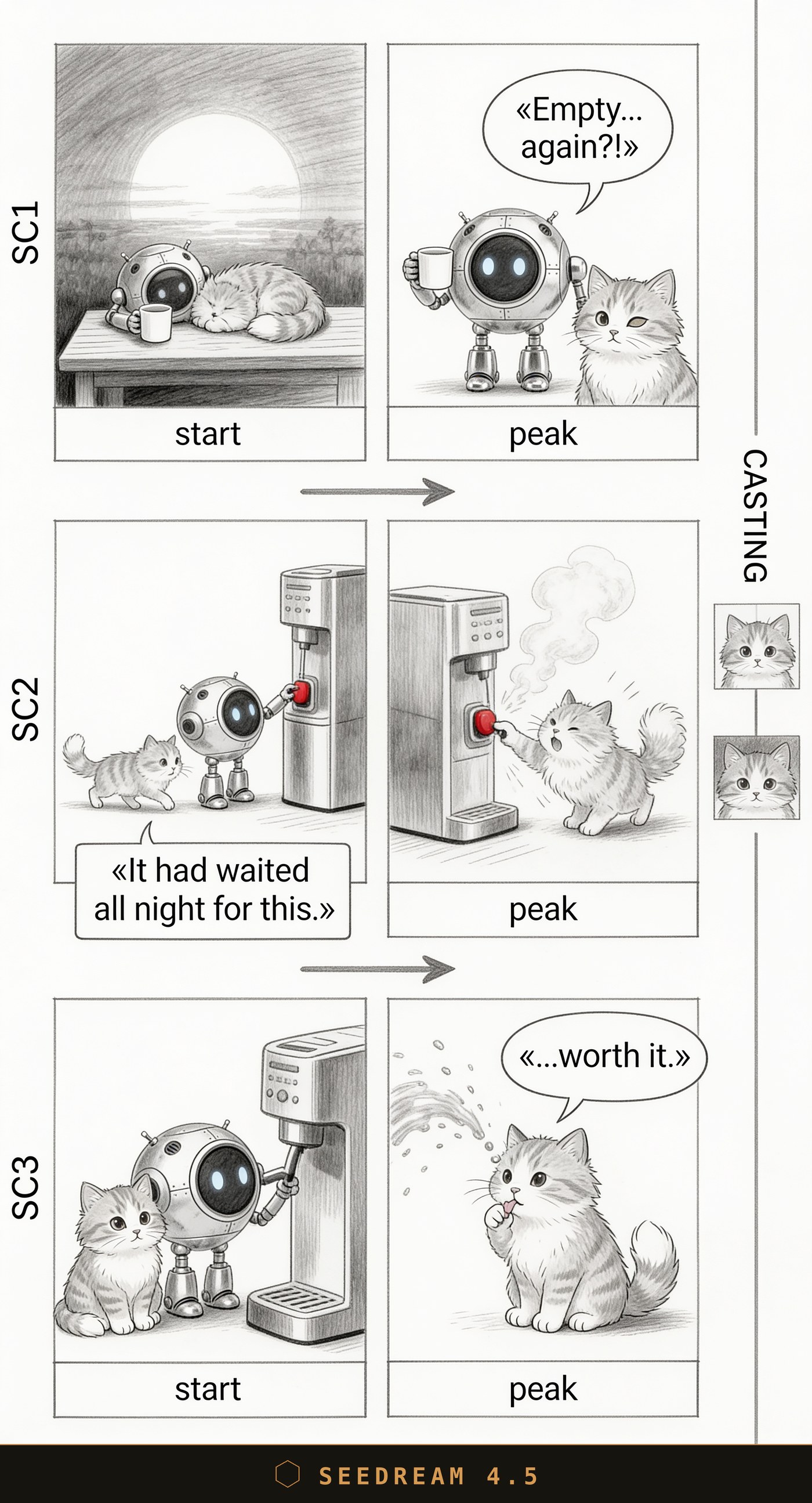
Seedream 4.5: а ось тут критична помилка. На фінальному кадрі робот узагалі зник, а його репліку «...worth it.» віддали коту. Жарт про облитого кавою робота зламано — головного героя в панчлайні немає.
Короткий підсумок
| Модель | Сильне | Слабке | Де в мене |
|---|---|---|---|
| Nano Banana 2 | Стабільний каст, дослівний текст з ялинками, чиста розкадровка | — | Робочий вибір зараз |
| GPT Image 2 | Найкраща деталізація і фактура | Репліки без ялинок, кадр щільніший | Порекомендую, якщо вийде дешевше за Nano Banana 2 |
| Nano Banana Pro | Чисто, каст тримає | З досвіду повільніше й дорожче | Запас, коли не шкода часу |
| Seedream 4.5 | Приємний «скетчевий» стиль | Критичні помилки: червона кнопка замість грейскейла, губить героя і віддає репліку не тому | Повз — помилки ламають сцену |
Висновок простий. Для розкадровки мені найважливіше, щоб модель рівно робила, що просять: тримала грейскейл, точний текст і каст. За цим критерієм Nano Banana 2 у мене зараз у проді — вона не помиляється на головному. GPT Image 2 малює найкрасивіше, і якщо виявиться дешевшою, я порекомендую її за деталізацію. Nano Banana Pro — міцний запас, але повільніше й дорожче. Seedream 4.5 відклав: стиль приємний, але критичні помилки на сцені мені дорожчі за красу.
Що в підсумку вийшло
Розкадровку я перевірив, пару реплік у сценарії поправив — і віддав сцену відеомоделі. Тій самій Seedance 2.0, на якій зупинився в другій частині. Ось результат: той самий робот, той самий кіт, ті самі біти — тільки вже в кольорі і зі звуком.
Від сірого олівцевого плану до готового кадру. Сценарій я узгодив іще на сторіборді — відеомоделі лишилося тільки відмалювати.
Де це в серії
Склався ланцюжок. У першій частині я обирав сценариста — він задає стелю якості тексту. У другій — відеомодель, вона його виконує. Розкадровка стала між ними: шар, де я нарешті бачу весь ролик заздалегідь і можу його поправити, поки правка коштує копійки. Раніше я довіряв пайплайну наосліп. Тепер дивлюся й вирішую.